An Approach To Construct Curated Processed Dataset for Data Analytics
This article explains an extensible and generic design to produce processed dataset which will be used as an input to data analytics system.
Join the DZone community and get the full member experience.
Join For FreeOrganizations in today’s world have increased focus on data as a tool to perform various kinds of profound analysis to extract vital outcomes, which will help organizations make the right decision to define future strategies.
For the success of an organization in today’s world, having the right data processing strategy on all the organization’s data to harness and extract different kinds of perspectives and information is becoming paramount to the success of the organization.
The key objective for the analytics program is to use the organization data to generate different kinds of extensible summarization, which can be further leveraged to perform several kinds of analytics to get the health of the organization and to determine the Achilles heel for the organization as well to know the strength areas. Further, the organization can leverage its strength to resolve the pain areas and the Achilles heel to take the organization into a dominant position where it can traverse into an upward trajectory to meet the aspirations of its customers and fulfill its objective. A few of the key analytics that can be performed on the data to extract vital outcomes are listed below:
- Trend and variance analysis on vital and critical data elements.
- Profitability analysis and Return on Investment analytics.
- Top profitable instruments for the organization in their respective domain and the performance of these instruments over a certain period.
- Top non-profitable instruments for the organization
- Instruments turning from one category to another category, for example, a list of top instruments by revenue or other key metrics moving from profitable to non-profitable category and vice versa.
- Performance of the departments and key contributor to overall organization profitability.
- Newly introduced Instruments performance and monitoring to tweak any anomaly so it can move into a successful track.
- Customer Analytics:
- Customer Trending
- Customer Interest
- Profitability by customer segment
- New Customer Segmentation
Listed above are a few analytics use cases that can be contemplated and prioritized for implementation. We can have many more such analytics requirements for an organization to be prioritized as per the organization's objective.
The focus of this article is not to discuss these analytics use cases but how the underlying processed, curated, and succinct dataset needed for the analytics can be prepared and made readily available to the analytics platform to define this analytics logic.
The key focus is to have the processed data in an extensible and generalized structure so that any type of analytics requirement can be easily implemented without much of the data processing to be implemented for any new initiative. We have experienced that setting up the processing requirements takes more time than implementing the analytics requirement.
To achieve this, I will propose a very extensible and loosely coupled design that can be taken as a reference architecture and should be tweaked and fine-tuned as per the organization's analytics need to incorporate the data processing and readiness for analytics. This will help the organization to have the processed data readily available in the form of generic and extensible summarized processed outputs to quickly implement analytics on top of it. This design will provide organizations with the ability to roll out any new analytics requirement in a very agile manner, thus substantially reducing the overall implementation cycle.
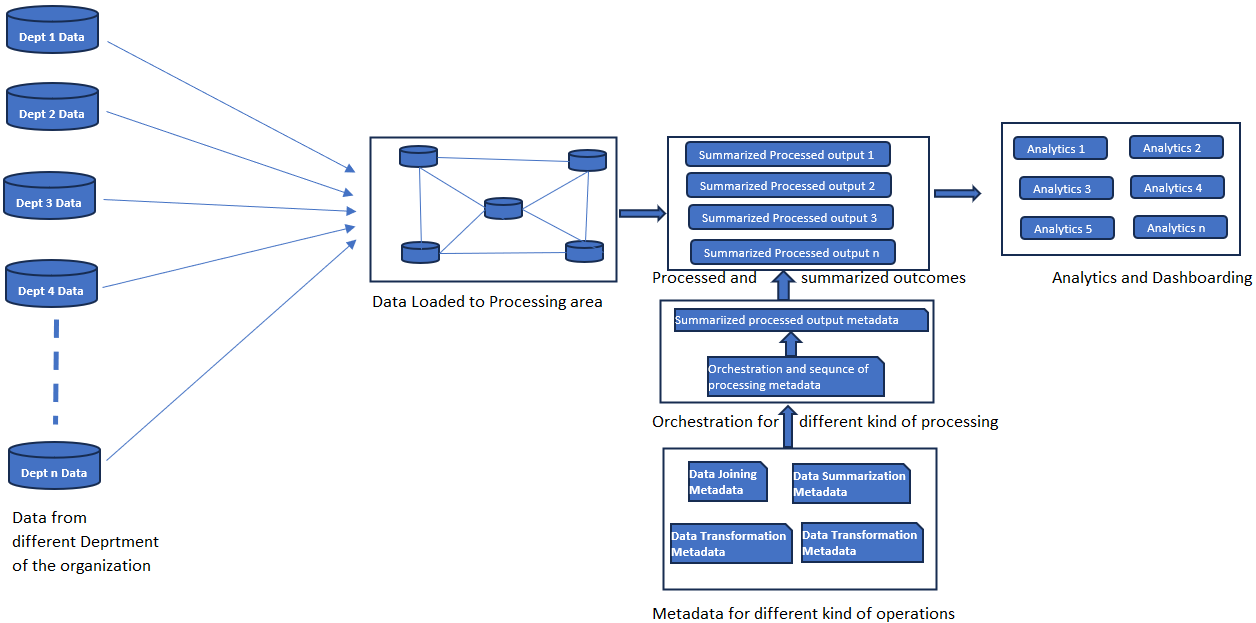
The overall processing structure is divided into four parts:
- Source the raw data from all the upstream departments to have it collated in one place. This can be called the data store for analytics data processing or a generic data lake, which contains all the data for the organization in one place. If such a data store is already existing for the organization, it can be leveraged to perform data processing for analytics.
- Setting up the basic processing logic as a loosely coupled metadata element. In this step, the collated data will be processed to generate generic structures that can be leveraged by downstream analytics applications to perform any kind of analysis. In this step, the system will leverage the already configured logic to perform the processing. Generally, speaking at a high level, four distinct kinds of operations are seen to be performed:
- Transform the source data to translate the values of the attributes from the source domain to the resultant domain. One example of this can be we are getting the customer details and transaction details from the respective department. Next, we need to bucket customers into separate categories based on the different customer buckets defined and to be used for analytics. This will require generating the customer bucket for every customer record and tagging the customer bucket for the customer. This might be used in subsequent analytics to produce various kinds of analytics outcomes for different customer buckets. To compute the customer bucket, we will be configuring the customer bucketing rules, which will be used and applied to every customer record to determine its respective customer bucket and tag the bucket to every customer. The customer bucket will be one analytics dimension in the resultant processed outcome, which will be one crucial facet of the analytics.
- Combining different datasets into one single dataset can be leveraged for subsequent processing. One example is Customer data comes from one department, which maintains all the customers for the organization. Next, the products purchased by the customers are residing in some other department. The next step is to combine these two datasets to have a combined view available, having the customer traits along with the product characteristics in the same record. To achieve this, we must combine customer and financial transactions. Similarly, all different kinds of join operations can be configured in this component, which provides the ability to configure any kind of join operations and can be used at runtime to define the processing pipeline. In this step, we will configure all types of data combining strategies that will be picked and used for different kinds of processing needs. Different combinations of hybrid data sets will be produced and used for the intended purpose. All combinations of the joined datasets will be available to the analytics system to apply analytics on top of it.
- Different kinds of transformation rules can be configured for translating the input data into the reportable domain. The balance computation and derived measure computation can also be defined as transformation rules in the framework metadata.
- Another important type of processing is data summarization, which will define the logic to aggregate the dataset into a smaller volume to provide concise and summarized outcomes for analytics. This component will provide the ability to configure any kind of aggregation logic on any dataset. Also, various kinds of summarization can be configured on the same dataset to provide different kinds of summarized outputs. The summarized outcomes will have succinct and concise results that can be readily consumed by the analytics application to generate informed outcomes for the users. This will help the report rendering to be very optimal as all the heavy processing is already taken care of as part of the prior step to have the processed data available for analytics.
- Next is the sequence to apply to the processing. All the above-mentioned four steps can be sequenced in any order based on the processing needs. The framework should provide the ability to define any processing sequence and to link the steps as per the requirement. Many kinds of processing can be defined on the same underlying data to generate different kinds of outcomes. The summarized outcomes will be stored separately, as depicted in the below flow, and will be available to downstream analytics systems to generate required analytics outcomes. These ready-to-use results will be extensible and can be used for different purposes. These structures can be extended or tweaked just by changing the underlying processing metadata logic. The system will be highly agile and extensible and will allow the users to incorporate any processing change easily and with a quick turnaround time.
Leveraging this design, an organization can preconfigure all the processing components, and based on the processing needs, the preconfigured components can be linked together as per the processing sequence to generate the summarized curated output, which can be sent to analytics tool to generate the required output in the form of visualization as well as detail reports.
We will take one example to explain for a retail organization dealing mainly with e-commerce business. Say the organization has a customer repository and daily transaction details for the customer going to one dataset. Now, we are asked to develop an analytics report to compute the daily growth as well as monthly growth in business for the top 1000 customers for a user-supplied duration.
Again, to compute the growth for the top customers, we need to apply the growth computation logic to the grain of the daily data, whereas to compute monthly growth we need to first have the grain of customer data at the month level to compute the growth. So, this is one example where the type of computation will be dependent on the grain of data. To achieve these types of niche use cases. We need to have the base data available and the aggregation or no-aggregation logic in place. Next, we will decide, based on the use case, whether we need to aggregate or not aggregate. To compute the above-given case, we will have slight variations in the processing as listed below:
- Use Case: Daily growth in business for the top 1,000 customers for a given month:
- Extract the daily data for the given month for the customers who have done maximum business.
- Apply the growth logic directly on the given data to compute the growth measure and add it to the record.
- Persist the data to be consumed by the analytics to show the growth statistics in the form of analytics reports.
- Use Case: Monthly growth in business for the top 1,000 customers for a given year at the grain of key customer dimension attributes provided by business:
- Extract the daily data for the given month for the customers who have done maximum business.
- Summarize the data on a monthly basis for the given set of customers at the grain of the provided customer dimensions.
- Apply the growth logic directly on the monthly aggregated data to compute the monthly growth measure and add it to the record.
- Persist the data to be consumed by the analytics to show the growth statistics in the form of analytics reports.
Few key points to mention when looking into the above two use-cases:
- The same data is leveraged for both scenarios.
- The only difference is applying the processing logic, which in this case is the growth computation requirement at separate grains of data.
- If the volume of the customer base is very large, it runs into multi-million customers for large organizations. Generating this curated output on the fly for analytics will take time to process.
- Pre-processing and having the resultant dataset readily available to apply analytics is what will make the process very competent and optimum.
- One approach to solve this requirement is to take the base data and have it available at all the required grains and plug in the processing logic to the required grain.
- This will be a good approach if we know beforehand about all the different grains of the data to be available for all kinds of processing logic in the processing ecosystem.
- For transformation and computation to be applied to what grain is like in the above scenario, we need to compute growth at both the grain of daily and monthly datasets. Framework should provide the ability to map the computation and transformation rules to the grain needed for the logic.
- Even if any computation needs to be applied at a hybrid grain where we need to join the dataset at different grains based on some join key, it is to be supported. The system should provide the ability to combine daily datasets with monthly and post that apply the computation logic, which requires attributes from both monthly and daily datasets together in the same processing logic.
- This all can be achieved by first defining the different grains, i.e., lowest grain, multiple intermediate grains at the combination of required dimensions, and hybrid grain, requiring combining the dataset at different grains to produce hybrid grain.
- Next, the computation processor is to be defined and mapped to the grain where they need to be applied.
- Compute and have the curated output dataset available and persisted for analytics consumption.
- This way, we can generate very generic result sets for the analytics computation.
- Any change to computation logic can be achieved very seamlessly with just a change in the underlying configuration.

In the above diagram, we are depicting the design where tech and business users will configure all four building blocks for the data processing:
- All the required data extraction logic in the form of extraction metadata from various upstream applications and departments of the organization
- All required aggregation logic is in the form of aggregation metadata. This will comprise of aggregation on various datasets and configured in a generic manner to be plugged into any processing pipeline.
- All the Data joiner logic for the in-scope datasets join scenarios will be configured in the form of Joiner metadata. This will again be configured as a decoupled piece, which can be plugged into any processing pipeline.
- All the transformation, computation, and data conversion logic will be configured in the form of transformation rules metadata. These rules will be modeled as a generic logic that can be plugged into and applied on any compatible dataset to provide the transformed value. Again, this can be plugged into any processing pipeline.
All the above-listed four categories of logic will be defined as generic, reusable, and configurable metadata in the respective metadata repositories.
When there is a need to implement a processing pipeline for any analytics reporting purpose, these repositories will be referred to pick and choose the required logic residing in the form of generic and reusable metadata. The identified set of logic from the above four categories will be bundled together as per the required processing sequence to design the processing pipeline.
This framework will provide the ability to the technology team to quickly onboard any processing pipeline by reusing the individual piece of logic from the existing metadata repositories.
This architecture will help to provide an expedited route to respond to any processing logic change as well as onboard any brand-new processing requirement from scratch.
The four sets of repositories mentioned above can be enhanced and extended with any new requirement and, with time, will become very comprehensive and rich with all the different kinds of logic available within the repositories. The framework should provide the ability to efficiently search the right logic step from the repository as it will grow over time and will contain a huge set of logic metadata.
Conclusion
The framework discussed in this article is an extensible strategy to build any data processing infrastructure in a very agile manner. The framework is built on the basic constructs of reusability, extensibility, metadata-driven, and configurable, as well as decoupled and mutually exclusive pieces of logic. The core of the design is to assess the overall processing requirement, split the entire processing requirements into smaller fragments, allocate them to the right processing category, and configure those smaller pieces in their respective repositories, as discussed in the above flow diagram. These repositories will be decoupled to any implementation and can be reused for multiple processing implementations, thus providing the ability to reuse and link to multiple processes. The four categories of processing repositories discussed in this article are not fixed and are taken as an illustration to explain the concept. In the actual implementation of this design for any organization, the processing categories can be defined based on disparate processing patterns identified for the processing ecosystem of the organization. Hope this article presented some unique perspectives to the developers and architects who are venturing into any new endeavor to implement a processing framework for reporting and analytics. The discussed design can be contemplated and taken into consideration as a reference framework while designing an optimal solution for the organization. Please write to me in case of any clarification or response needed for any concept explained in this article.
Opinions expressed by DZone contributors are their own.
Comments