An Effective Mechanism for Preliminary Analysis on the Effects of Propensity To Trust in Distribution Software Development
Explore traits of different personalities representing an individual disposition to perceive another as trustworthy.
Join the DZone community and get the full member experience.
Join For FreeThe abstract of this study has established trust is a crucial change for developers, and it develops trust among developers working at the different sites that facilitate team collaborations when discussing the development of distributed software. The existing research focused on how effectively to spread and build trust in not the presence of face-to-face and direct communications that overlooked the effects of trust propensity, which means traits of different personalities representing an individual disposition to perceive another as trustworthy. The preliminary quantitative analysis has been presented in this study to analyze how the trust propensity affects the collaboration success in the different distributed projects in software engineering projects. Here, the success is mainly represented through the request of pull that codes contribute, and changes are successfully merged to the repository projects.
1. Introduction
In global software engineering, trust is considered the critical factor affecting software engineering success globally. However, decreased trust in software engineering has been reported to:
- Aggravate the separated team's feelings by developing conflicting goals
- Reduce the willingness to cooperate and share information to resolve issues
- Affect the nature of goodwill in perspective towards others in case of disagreements and objections [1]
Face-to-face interactions (F2F) in current times help to grow trust among team members, and they successfully gain awareness related to both in terms of personal aspects and technical aspects [2]. On the contrary, the F2F interaction is more active now, which may be reduced in software-distributed projects [3]. Previous empirical research has shown that online or social media interactions among members over chat or email build trust among team members of OSS (open-source and software projects) that mainly have no chance related to meeting with team members [4].
Furthermore, a necessary aspect, especially for better understanding the trust development and cooperation in the working team, is the simple way of "propensity to trust" [5]. It is spreading the personal disposition of an individual or trust or taking the risk internally addicted to the trustee's beliefs and will behave as evaluated and expected [6]. However, the propensity of trust also refers to team members or individuals who generally tend to be perceived by others as trustworthy [7]. Moreover, we formulated the supporting research questions for this study that include as:
- Research Question (RQ): How does the propensity of trust of individuals facilitate successful collaboration even in software globally distributed projects?
The most common limitation of this research is its relevance to empirical research findings based on supporting trust [8]. The trust represents no explicit extent measures to which individual developers' trust directly contributed to the performances of projects [9]. However, in this study, the team mainly intended to overcome the supporting limitation by approximating overall project performances, including duration, productivity, and completion of requirements. Through successful collaborations, the researcher's team indicated a situation where mainly two developers are working together and developed cooperation successfully due to yielding the supporting project advancement through adding new features or fixing bugs. By such nuanced and supporting gain unit analysis, the research aim is to measure more directly how trust facilitates cooperation in distributed software projects.
Modern distributed and software projects support their coordination and workflow in remote work with the best version of control systems. The supporting pull request is considered the popular best way to successfully submit contributions to projects by using the distributed new version of the control system called Git. Furthermore, in reference to the development of pull-based development and model [10], the central repository of projects is to avoid the share among the different developers. On the contrary, developers mainly contributed through forking, that is, cloning repositories and successfully making the changes from each other. The primary condition and working of the pull repository is that when a set of supporting changes is successfully ready to finally submit the results into the central repository at that time, potential contributors mainly create the supporting pull request. After that, an integration manager, also known as a core developer, is effectively assigned the responsibility to individuals to inspect the integrated change in line with the project's central development. While working on software-distributed projects, an integration manager's main role is to ensure the best project quality. However, after the pull repository contribution's successful receipt, the pull request was closed, which is suitable for projects. That means the request of pull is either changed and accepted are integrated into the repository of the leading project or can be considered incorrect that considered as the pull request is changed or declined are rejected. Whether declined or accepted, the request for closed pull requires that the consensus is successfully reached by discussion. Furthermore, project managers also use the development collaborative platforms, including Bitbucket and GitHub, that make projects easier for developers or team members to collaborate by pull request [11]. It helps to provide a supporting and user-friendly interface web environment for discussing the supporting or proposed changes before the supporting integrating them into the successful source code of the project.
Accordingly, researchers represent the successful collaborations between the individual developers concerning accepting the request of pull and refine the best research question as supporting or follows:
- Research Question (RQ):How does the propensity of trust of individuals facilitate successful collaboration even in software globally distributed projects?
The researchers successfully investigated the refined questions of this research by analyzing the contributions history of pull requests from the famous developers of project Apache Groovy. Apache Groovy mainly provides archived supporting history through email-dependent communications. Researchers analyze the trace interactions over the supporting channels that assess the developers in an effective way known as “Propensity to trust."
The remainder of this research paper is well organized: the next section mainly discusses the challenge and supporting solutions to propensity quantifying trust. In sections three and four, researchers described the supporting empirical study and related its results. In the fifth section, researchers discuss the limitations and findings. At last, the research finally drew a conclusion and better described the future in the sections of this research.
2. Background
Measuring the Term “Propensity To Trust”
The five-factor or big five personality effective model is used as a general taxonomy to evaluate personality traits [12] mentioned in Figure 1. It includes supporting higher levels such as openness, extraversion, conscientiousness, neuroticism, and agreeableness. However, each higher-level dimension has six supporting subdimensions that are further evaluated according to the supporting dimensions [13]. Previous research has confirmed personality traits that can be successfully derived from practical analysis of emails or written text [14]. According to Tausczik & Pennebaker [15], in the big five models, each trait is significantly and strongly associated with theoretically appropriated word usage patterns that indicate the most substantial connection between personality and language use [16].
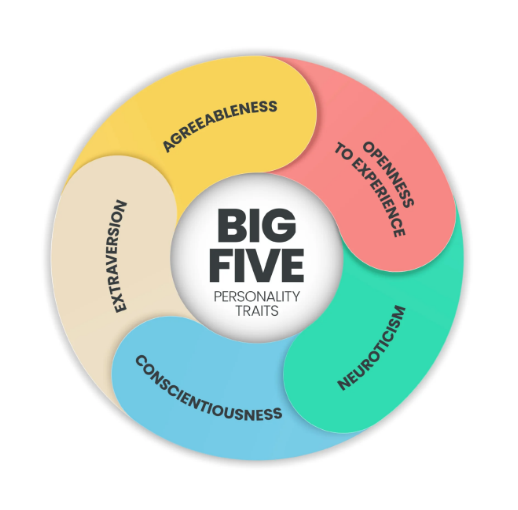
Figure 1: Big-Five traits of personality model
(Source: Developed by learner)
Furthermore, the existing research based on trust has directly relied on data self-reported through survey questionnaires that help to measure the trust of individuals on the supporting given scale [17], [18], and [19]. In addition, one of the reliable and notable exceptions is mainly represented through the supporting work of Wang and Redmiles [7], who successfully studied how trusts mainly spread in the supporting OSS projects. The researchers use the word count and linguistic inquiry psycholinguistics dictionary to help analyze and better use in supporting writing [15] and [20].
The trust quantitative measure is obtained based on the critical term “Tone Analyser”, an LIWC IBM Watson service leveraging. However, which uses the supporting linguistic analysis that helps to detect the three significant types of supporting tones from supporting written text, including writing, emotional, and social style, it is significantly driven by social tone measures to connect with the social tendencies in supporting the people writing (that is a trait of a big personality). In supporting ways, researchers focused on agreeableness recognition, one of the personality traits that indicated the tendency of people to be cooperative and compassionate towards others. However, one supporting trust related to agreeableness is trusting others to avoid being suspicious [21] efficiently. About the following, the researcher uses agreeable personality traits similar to proxy supporting measures of an individual's propensity to trust.
Factors Influenced the Acceptance of Pull-Requests
According to [22] and [23], the factors influencing the contribution acceptances related to requests are considered both technical and social. Both factors include technical and social factors explained in context with the pull request.
Technical aspects, the existing research based on patch acceptance as mentioned in [24], code reviewing, and bug training as mentioned in [25] and [26], has analyzed that the contribution of merge decision is directly affected through both project size such as team and KLOC size including the patch itself. Similarly, according to [10], it was analyzed that approximately 13% of pull requests reviewed were successfully closed to avoid merging, especially for supporting or purely technical reasons. However, the researchers found the supporting decision related to merging was mainly affected by the changes involving supporting code areas actively under coverages and developing test attached cases.
With the increasing demand for social and transparent coding platforms, including GitHub and Bitbucket, integrators refer to contribution quality by looking at both technical and quality and developing track records through acceptance of previous contributions [27]. Numbers of followers and stars in GitHub reputations as auxiliary indicators [28]. However, the iterating findings related to pulling requests are explored as "treated equally" related to submitters defined as "social status." That is whether the external contributors are the core team members' core development. Furthermore, Ducheneaut [30] examined that the main contribution directly comes from the submitters, who are also recognized as the core development teams, driving the higher chances of acceptance and using the supporting records of signal interactions for judging and driving the proposed changes in quality.
Finally, the supporting findings help to provide compelling further motivations to others for looking at the non-technical and other factors that can influence the decision to merge the supporting pull request effectively.
3. Empirical Study
Researchers designed the study effectively to quantitatively access and analyze the impact of trust propensity to pull requests or (PRs) acceptance. However, the researchers used the simple and logistic regression that helped to build the model, especially for estimating the success or probability of the supporting merged or pull request that given the propensity integrators to trust. That means it is agreeableness as measured through the analysis of IBM Watson Tone. Moreover, in our supporting framework, researchers treat the pull request acceptances as the supporting dependent variables, including the independent variables as measures of agreeableness integrator that is a predictor.
For supporting the study, the two primary resources are successfully used to collect the data information that is pulled, especially in GitHub, and the second emails retrieved, especially from the project of Apache Groovy. The project is considered object-oriented programming used for the Java platform, and scripting languages are also used for the Java platform. However, among several projects, this project is supported through Apache Software Foundations. Researchers opportunistically chose Groovy due to:
- It can make faster mailing and archives freely accessible.
- It can follow a supporting pull request and rely on the development model.
Dataset
The researchers used the supporting database of GHTorrent to collect the information in chronological order to support lists of pull requests [31]. It opened based on GitHub, and for each request of pull, researchers stored the supporting information, including:
- The main contributor
- The supporting data when it was accessible or opened
- The merged status
- The integrator
- The supporting data when it merged or closed
Not all the pull requests are supported by GitHub. The researchers looked at the comments of pull requests, as mentioned, to identify the closed and merged that are outside of the supporting GitHub. In support, the researchers searched especially for the presences related to:
- Main branch commits that closed related to pulling requests
- Comments, especially from the manager's integration who supported the acknowledgment of a successful merge
Researchers reviewed all the pull request projects one by one and evaluated their status annotated and manually. Automated Albeit reviews similar procedures that help describe in [10].
Furthermore, the description related to the Apache Groovy project is shown in Table 1.
|
DESCRIPTION
|
FOR JAVA-SUPPORTING PLATFORMS, OBJECT-ORIENTED PROGRAMMING IS THE PREFERRED LANGUAGE
|
|---|---|
| Languages | Java |
| Number of project committers | 12 |
| PRs based on GitHub | 476 |
| Emails successfully achieved, especially in the mailing list | 4,948 |
| Unique email senders | 367 |
Table 1: Apache Groovy Project description
(Source: Developed by learner)
From Table 1, researchers almost drive the 5,000 messages from project emails and use my stats' supporting tools to mine the supporting users and drive the mailing list. It is available on the websites of Groovy projects. The researchers first retrieve the committer's identities, which are core team members, including the writer who accesses the supporting repository. It was retrieved from the Groovy projects web page hosted at Apache and GitHub. Furthermore, researchers compared the names and IDs of users to integrate the pull request and shared the mailing list names. After that, researchers are able to identify the supporting messages from the ten integrators. Lastly, the team is filtered out by developers who mainly exchange up to 20 supporting mains in a specific time period.
Integrators of Propensity To Trust
Once the researchers successfully obtained the supporting mapping related to the communications records of team developers and core team members, they successfully computed the healthy scores of propensity to trust from the supporting content related to the entire corpus of emails. In support, researchers or developers process email content through the tone of Analyzer and obtain the agreeableness score. That is defined as the interval of 0 and 1. The supporting value is obviously smaller than one that is 0.5, associated with lower agreeableness. Therefore, it tends to be less cooperative and compassionate towards others. The values equal and more than 0.5 are directly connected with higher agreeableness. However, in the end, the high and low agreeableness scopes are considered by researchers or developers to drive the level of propensity trust integrators analyzed in Table 2.
4. Results
In this section, researchers present the supporting results through a regression model to build a practical understanding of the propensity to trust. It is a predictor and pulls request acceptances. The researchers performed the regression simple logistics through R statistical and supporting packages. In Table 3, the analysis of results is reported, and researchers omit to evaluate the significant and positive efforts related to control variables, including #emails and #PRs reviewed to send because of space constraints. The results include the coefficient estimate related to + 1.49 and add odds ratio of 4.46 with drive statistical significance, including a p-value of 0.0009.
Furthermore, the coefficient sign estimates and indicates the negative or positive associations related to the predictor, including the success of the pull request. In addition, the OR (odds ratio) weighs and drives the effect size that impacts closer to value one. It is a more negligible impact based on parameters based on the success of chance [32]. The results indicate trust propensity, which is significantly and positively associated with the probability of supporting pull requests that successfully merged.
Furthermore, researchers can use the estimated coefficients from the supporting model explored in Table 2 and the equations below. It can directly affect the merging probability and pull requests from the project of Groovy. However, the estimated probability of acceptance PR includes the following:
- PR estimated probability: 1/ (1 + exponential (-(+1.49+4.46 * trust propensity))).............(i)
From the above equation and example, the k pull request and probability acceptances through an integrator i with the supporting low propensity is 0.68. The overall PR correspondence increases as the results and supporting questions are analyzed.
5. Discussion
The discussion section is the best analysis of knowledge evaluated by researchers in their first attempts to drive the quantifying effects on the developer's trust and personal traits. It is based on distributed software projects by following a pull request supporting a based development model. Similarly, the practical result of this study is to drive the initial evidence to evaluate the chances related to merging the contributions code that is correlated with the traits of personality of integrators who performed well in reviewing the code. Furthermore, the novel finding underlines the supporting role played by the researchers or developers related to the trust of propensity through personality related to the execution of review code and tasks. The discussion results are linked with primary sources such as [22] and [30], mainly observed through the social distance between the integrator and social contributors to influence the acceptance changes through pull requests.
| Integrators | Reviewed PR: Merged |
Reviewed PR: Closed |
A score of propensity trust |
|---|---|---|---|
| Developer 1 | 14 | 0 | High |
| Developer 2 | 57 | 6 | |
| Developer 3 | 99 | 7 | High |
| Developer 4 | 12 | 4 | Low |
| Developer 5 | 10 | 1 | Low |
| Developer 6 | 8 | 0 | Low |
| Total | 200 | 18 | - |
Table 2: Score of Propensity to trust include pull request
(Source: Developed by learner)
| Predictors | Estimate of Coefficient | Odds Ratio | Supporting P-Value |
|---|---|---|---|
| Intercept | Plus (+) 0.77 | 0.117 | |
| Trust Propensity | Plus (+) 1.49 | 4.46 | 0.009 |
Table 3: Simple Logistic regression model results
(Source: Developed by learner)
From the supporting discussion and analysis of Tables 2 and 3, the developers mainly recommend making sure about the community before any contribution. The users mentioned in the supporting comments of the pull requests followed the recommendation explicitly to request the supporting review from the integrators [33]. It shows the willingness to help and cooperate with others to drive a higher trust propensity. The results and findings that PR accepted as p-value as 0.68. Moreover, the broader socio-technical framework congruences the research that finds the critical points for further studies and investigates far more as evaluated in research. The personality traits also match the needs of coordinates established with the help of technical domains supporting source code areas interested and evaluated with the proposed changes.
Finally, in the supporting discussion, because of its preliminary nature, some limitations are also suffered in this study regarding the result's generalizability. The researchers mainly acknowledge the preliminary analysis based on supporting tools and numbers to involve developers from the side of single projects. However, only through the supporting replications, including the different values of datasets and settings, will researchers be able to evaluate and develop evidence on solid empirical changes.
In addition, the other supporting limitation of this study is around the propensity validity and trust construct. Due to less practicality, researchers mainly decided to not only depend on the self-reported and traditional psychometric approaches that are used for measuring trust, including surveys [12]. In a replication of future perspective, researchers will support and investigate the reliability of analyzer tone services that connect with the technical domain that includes the software engineering from longer time linguistic resources, which are usually evaluated and trained based on the content of non-technical.
6. Conclusion and Recommendation
Conclusion
Therefore, the research has included six major chapters (sections) to evaluate the research topic based on a preliminary analysis of the propensity effect to trust in supporting distributed software development. The first chapter includes an overview of research supporting critical and real-time information. The second chapter includes personality traits and a significant five-factor analysis to build trust in teamwork. The third chapter has highlighted the empirical study related to research by connecting the real supporting projects such as Apache Groovy projects. The fourth chapter focuses on analysis and results to drive the research and projects. The five chapters have been discussed based on results and empirical study. The last chapter, or sixth chapter, concludes the research with supporting the recommendation for further study.
This study represents the initial step in driving the broader research efforts that help collect the evidence of quantitative analysis and well-established trust among team members and developers and contribute to increased performances of projects related to distributed software engineering projects. In the analysis of personality models of the big five model, the trust propensity related to perceived others is driven by the trustworthy and stable personality traits that have changed from one person to another. Overall, the leveraging prior and supporting evidence that emerging personality traits unconsciously drive from the lexicon personally used in supporting written communications. The researchers and developers have used the tone of IBM Watson and analyzer services that help to measure the trust propensity by analysis of written emails archived through the projects of Apache Groovy. Furthermore, we found initial supporting evidence that researchers and developers who have posed with a higher propensity are likely to develop and trust more to accept the significant external contribution analyzed from the pull request.
Recommendation
For future work, it is recommended by researchers to replicate the supporting experiences to drive solid evidence. Researchers have followed and compared the analyzer tone, including the supporting tools, to better assess the reliability of research in extracting the personality, especially from the text that mainly contains the information of technical content. The researchers intended or used to enlarge the supporting database for both projects and supporting pull requests to understand the research better. It suggests that developers' personalities will change by relying on the project's participants and developing mutual trust through involving pairs of developers who mainly interact in supporting dyadic cooperation.
For future study, it is suggested that developers of distributed software engineering projects use the network-centric approach, especially for estimating the supporting trust between software developers and open sources. Developers will follow the study's three stages of the network-centric approach to build trust while working from different physical locations globally on the distributed software engineering project. The first stage will be CDN (community-wide network developers) of this approach, which means community-wide network developers to construct better the information connecting to projects and developers. The second stage will compare the supporting trust between the supporting pairs directly linked to developers with the CDN. The last stage is computed with the trust between the developer pairs indirectly linked in the CDN.
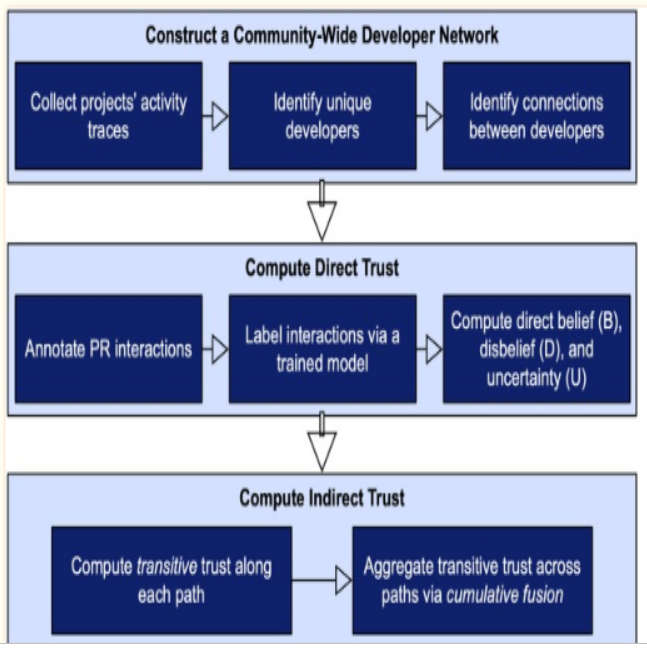
Figure 3: Future suggestion for a network-centric approach for estimating the trust
(Source: Developed by learner)
From Figure 3 above, CDN is the main stage connected with the other two stages to build trust and trustworthiness to drive potential contributions to an OSS project. The developers or researchers can construct the network-centric approach by focusing on CDN that provides supporting and valuable information about the effective collaboration between the OSS community and developers. The role of CDN in Figure 3 represents the community of developers driven by the OSS multiple projects that share some most common characteristics, including the same case and programming languages.
Furthermore, developers or researchers can follow the main four features to label the supporting data to the regression train models for feature extractions. Word embedding can be used by developers such as Google Word2Vec to analyze and vectorize every comment to avoid the pre-trained model. The developers can train their own Word2Vec model related to data of software engineering to drive domain-specific and supporting models to better semantic representation analysis. It can be compared with the pre-trained and generic models. The developers can also use the 300 vector dimensional models to get comments and evaluate the vector representation. In addition, social can also be considered a strength for developers to build a connection between two or more developers to influence trust. Researchers and developers can assign the supporting integer values, especially for every role, to build the pull request and analyze the comment to build trust among individuals.
References
- [1] B. Al-Ani, H. Wilensky, D. Redmiles, and E. Simmons, “An Understanding of the Role of Trust in Knowledge Seeking and Acceptance Practices in Distributed Development Teams,” in 2011 IEEE Sixth International Conference on Global Software Engineering, 2011.
- [2] F. Abbattista, F. Calefato, D. Gendarmi, and F. Lanubile, “Incorporating Social Software into Agile Distributed Development Environments.” Proc. 1st ASE Workshop on Social Sofware Engineering and Applications (SOSEA’08), 2008.
- [3] F. Calefato, F. Lanubile, N. Sanitate, and G. Santoro, “Augmenting social awareness in a collaborative development environment,” in Proceedings of the 4th international workshop on Social software engineering - SSE ’11, 2011. [4] F. Lanubile, F. Calefato, and C. Ebert, “Group Awareness in Global Software Engineering,” IEEE Softw., vol. 30, no. 2, pp. 18–23.
- [5] A. Guzzi, A. Bacchelli, M. Lanza, M. Pinzger, and A. van Deursen, “Communication in open source software development mailing lists,” in 2013 10th Working Conference on Mining Software Repositories (MSR), 2013.
- [6] Y. Wang and D. Redmiles, “Cheap talk, cooperation, and trust in global software engineering,” Empirical Software Engineering, 2015.
- [7] Y. Wang and D. Redmiles, “The Diffusion of Trust and Cooperation in Teams with Individuals’ Variations on Baseline Trust,” in Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, 2016, pp. 303–318.
- [8] S. L. Jarvenpaa, K. Knoll, and D. E. Leidner, “Is Anybody out There? Antecedents of Trust in Global Virtual Teams,” Journal of Management Information Systems, vol. 14, no. 4, pp. 29–64, 1998.
- [9] J. W. Driscoll, “Trust and Participation in Organizational Decision Making as Predictors of Satisfaction,” Acad. Manage. J., vol. 21, no. 1, pp. 44–56, 1978.
- [10] G. Gousios, M. Pinzger, and A. van Deursen, “An exploratory study of the pull-based software development model,” in Proceedings of the 36th International Conference on Software Engineering - ICSE 2014, 2014.
- [11] F. Lanubile, C. Ebert, R. Prikladnicki, and A. Vizcaino, “Collaboration Tools for Global Software Engineering,” IEEE Softw., vol. 27, no. 2, pp. 52–55, 2010.
- [12] P. T. Costa and R. R. McCrae, “The Five-Factor Model, Five-Factor Theory, and Interpersonal Psychology,” in Handbook of Interpersonal Psychology, 2012, pp. 91–104.
- [13] J. B. Hirsh and J. B. Peterson, "Personality and language use in self-narratives," J. Res. Pers., vol. 43, no. 3, pp. 524–527, 2009.
- [14] J. Shen, O. Brdiczka, J.J. Liu, Understanding email writers: personality prediction from email messages. Proc. of 21st Int’l Conf. on User Modeling, Adaptation and Personalization (UMAP Conf), 2013.
- [15] Y. R. Tausczik and J. W. Pennebaker, "The Psychological Meaning of Words: LIWC and Computerised Text Analysis Methods," J. Lang. Soc. Psychol., vol. 29, no. 1, pp. 24–54, Mar. 2010.
- [16] B. Al-Ani and D. Redmiles, “In Strangers We Trust? Findings of an Empirical Study of Distributed Teams,” in 2009 Fourth IEEE International Conference on Global Software Engineering, Limerick, Ireland, pp. 121–130.
- [17] J. Schumann, P. C. Shih, D. F. Redmiles, and G. Horton, “Supporting initial trust in distributed idea generation and idea evaluation,” in Proceedings of the 17th ACM international conference on Supporting group work - GROUP ’12, 2012.
- [18] F. Calefato, F. Lanubile, and N. Novielli, “The role of social media in affective trust building in customer–supplier relationships,” Electr. Commerce Res., vol. 15, no. 4, pp. 453–482, Dec. 2015.
- [19] J. Delhey, K. Newton, and C. Welzel, "How General Is Trust in 'Most People'? Solving the Radius of Trust Problem," Am. Social. Rev., vol. 76, no. 5, pp. 786–807, 2011. [20] Pennebaker, James W., Cindy K. Chung, Molly Ireland, Amy Gonzales, and Roger J. Booth, "The Development and Psychometric Properties of LIWC2007," LIWC2007 Manual, 2007.
- [21] P. T. Costa and R. R. MacCrae, Revised NEO Personality Inventory (NEO PI-R) and NEO Five-Factor Inventory (NEO FFI): Professional Manual. 1992.
- [22] J. Tsay, L. Dabbish, and J. Herbsleb. Influence of social and technical factors for evaluating contribution in GitHub. In Proc. of 36th Int’l Conf. on Software Engineering (ICSE’14), 2014.
- [23] G. Gousios, M.-A. Storey, and A. Bacchelli, “Work practices and challenges in pull-based development: The contributor’s perspective,” in Proceedings of the 38th International Conference on Software Engineering - ICSE ’16, 2016.
- [24] C. Bird, A. Gourley, and P. Devanbu, “Detecting Patch Submission and Acceptance in OSS Projects,” in Fourth International Workshop on Mining Software Repositories (MSR’07:ICSE Workshops 2007), 2007. [25] P. C. Rigby, D. M. German, L. Cowen, and M.-A. Storey, “Peer Review on Open-Source Software Projects,” ACM Trans. Softw. Eng. Methodol., vol. 23, no. 4, pp. 1–33, 2014.
- [26] J. Anvik, L. Hiew, and G. C. Murphy, "Who should fix this bug?," in Proceeding of the 28th international conference on Software Engineering - ICSE '06, 2006.
- [27] L. Dabbish, C. Stuart, J. Tsay, and J. Herbsleb, “Social coding in GitHub: Transparency and Collaboration in an Open Source Repository,” in Proceedings of the ACM 2012 conference on Computer Supported Cooperative Work - CSCW ’12, 2012.
- [28] J. Marlow, L. Dabbish, and J. Herbsleb, “Impression formation in online peer production: Activity traces and personal profiles in GitHub,” in Proceedings of the 2013 conference on Computer supported cooperative work - CSCW ’13, 2013.
- [29] G. Gousios, A. Zaidman, M.-A. Storey, and A. van Deursen, “Work practices and challenges in pull-based development: the integrator’s perspective,” in Proceedings of the 37th International Conference on Software Engineering - Volume 1, 2015, pp. 358–368.
- [30] N. Ducheneaut, "Socialisation in an Open Source Software Community: A Socio-Technical Analysis," Comput. Support. Coop. Work, vol. 14, no. 4, pp. 323–368, 2005.
- [31] G. Gousios, “The GHTorrent dataset and tool suite,” in 2013 10th Working Conference on Mining Software Repositories (MSR), 2013.
- [32] J. W. Osborne, “Bringing Balance and Technical Accuracy to Reporting Odds Ratios and the Results of Logistic Regression Analyses,” in Best Practices in Quantitative Methods, pp. 385–389.
- [33] O. Baysal, R. Holmes, and M. W. Godfrey. Mining usage data and development artefacts. In Proceedings of MSR '12, 2012.
- [34] Sapkota, H., Murukannaiah, P. K., & Wang, Y. (2019). A network-centric approach for estimating trust between open source software developers. Plos one, 14(12), e0226281.
- [35] Wang, Y. (2019). A network-centric approach for estimating trust between open source software developers.
Published at DZone with permission of Nitin Kevadiya. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments