An Overview of Key Components of a Data Pipeline
Dive into how a data pipeline helps process enormous amounts of data, key components, various architecture options, and best practices for maximum benefits.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
With the consistent growth of data-driven applications, the complexities of consolidating data from multiple sources for streamlined decision making is often considered a key challenge. While data forms the foundation of analytics and operational efficiency, processing big data requires holistic data-driven strategies for real-time ingestion and processing. To help with this, data pipelines enable organizations to aggregate and analyze huge datasets by defining a series of activities that convert raw data into actionable insights.
In this article, we dive into how a data pipeline helps process enormous amounts of data, key components, various architecture options, and best practices to achieve the maximum benefits.
What Is a Data Pipeline?
A data pipeline is the collection of tasks, tools, and techniques used to process raw data. Pipelines consist of multiple interrelated steps connected in series, which enable the movement of data from its origin to the destination for storage and analysis. Once data is ingested, it is taken through each of these steps, where the output of one step acts as the input for the subsequent step.
In the modern technology landscape, big data applications rely on a microservice-based model, which allows monolithic workloads to be broken down into modular components with smaller codebases. This encourages data flow across many systems, with data generated by one service being an input for one or more services (applications). An efficiently designed data pipeline helps manage the variety, volume, and velocity of data in these applications.
Benefits of a Data Pipeline
Primary advantages of implementing an optimally designed data pipeline include:
IT Resource Optimization
When building infrastructure for data processing applications, a data pipeline enables the use of replicable patterns — individual pipes that can be repurposed and reused for new data flows, helping to scale IT infrastructure incrementally. Repeatable patterns also blend security into the architecture from the ground up, enabling the enforcement of reusable security best practices as the application grows.
Increase Application Visibility
Data pipelines help extend a shared understanding of how data flows through the system along with the visibility of the tools and techniques used. Data engineers can also set up telemetry for data flows within the pipeline, enabling continuous monitoring of processing operations.
Improved Productivity
With a shared understanding of data processing operations, data teams can efficiently plan for new data sources and flows, reducing the time and cost for integrating newer streams. Offering analytics teams comprehensive visibility of the data flows also enables them to extract meaningful insights, thereby helping to enhance the quality of data.
Key Components of a Data Pipeline
Data pipelines enforce the enrichment of data by moving it from one system to another, typically with different storage implementations. These pipelines enable the analysis of data from disparate sources by transforming and consolidating it into a unified format. This transformation consists of various processes and components handling diverse data operations.
Processes of a Data Pipeline
Although different use cases require different process workflows, the following are some common processes of a data pipeline:
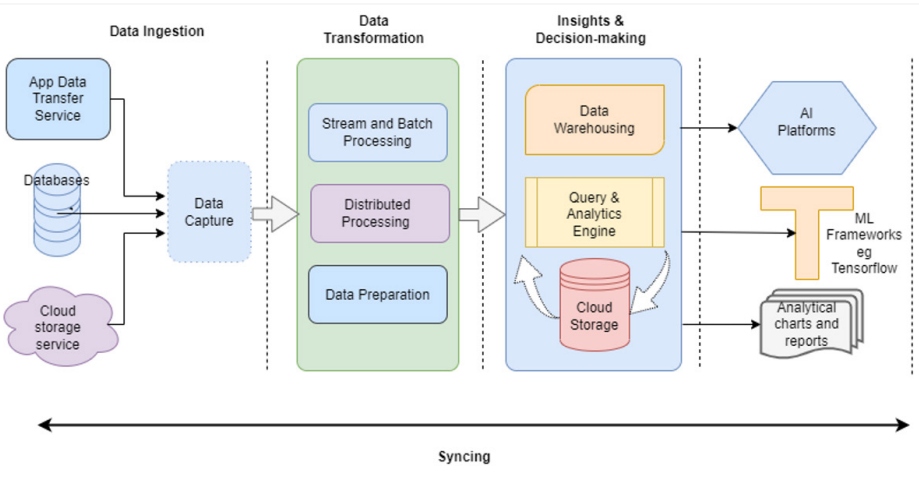
Stages of a Data Pipeline
Though the complexity of a data pipeline differs based on use case, amount of data to be churned, and the frequency of processing data, here are the most common stages of a data pipeline:
Extraction/Ingestion
This stage involves the ingestion of data from its origin, also known as the source. Data entry points include IoT sensors, data processing applications, online transaction processing applications, social media input forms, public datasets, APIs, etc. Data pipelines can also extract information from storage systems, such as data lakes and warehouses.
Transformation
This stage encompasses the changes that are made to the data as it moves from one system to another. The data is transformed to ensure it fits the format supported by the target system, such as an analytical application.
Processing
This stage includes all the activities involved in ingesting, transforming, and loading data to the target destination. Some data processing activities include grouping, filtering, aggregating, and augmenting.
Syncing
This process ensures the syncing of data across different data sources and the pipeline's endpoints. The stage essentially involves the updating of data libraries to keep data consistent across all stages of the pipeline's lifecycle.
Data Pipeline Architecture Options
The three primary design options for building data processing architecture for big data pipelines include stream processing, batch processing, and lambda processing.
Stream Processing
Stream processing involves ingesting data in continuous streams with data being processed in parts. This architecture's objective is a rapid processing approach that is meant primarily for real-time data processing with use cases such as fraud detection, log monitoring and aggregation, and user behavior analysis.
Batch Processing
With batch processing, data is collected over time and later sent for processing in batches. In contrast to stream processing, batch processing is a time-consuming approach and is meant for large volumes of data that are not needed in real-time. Batch processing pipelines are commonly deployed for applications such as customer orders, billing, and payroll.
Lambda Processing
Lambda processing is a hybrid data processing deployment model that combines a real-time stream pipeline with a batch processing data flow. This model divides the pipeline into three layers: batch, stream, and serving.
In this model, data is ingested continuously and fed into both batch and stream layers. The batch layer precomputes batch views and hosts the primary dataset. The stream layer handles data that has not been loaded to the batch view since batch operations are time-consuming. The serving layer creates an index of batch views so that they can be occasionally queried in low latency.
Components of a Data Pipeline
Key components of a data pipeline include:
- Data serialization – Data serialization defines standard formats that make data conveniently identifiable and accessible and is responsible for converting data objects into byte streams.
- Event frameworks – These frameworks detect actions and processes that lead to changes in the system. Events are logged for analysis and processing to assist in decisions based on application and user behavior.
- Workflow management tools – These tools help structure tasks within a pipeline based on directional dependencies. These tools also simplify the automation, supervision, and management of pipeline processes.
- Message bus – Message buses are one of the most crucial components of a pipeline, allowing for the exchange of data between systems and ensuring compatibility for disparate datasets.
- Data persistence – The storage system where data is written onto and read from. These systems enable the unification of various data sources by enabling a standard data access protocol for different data formats.
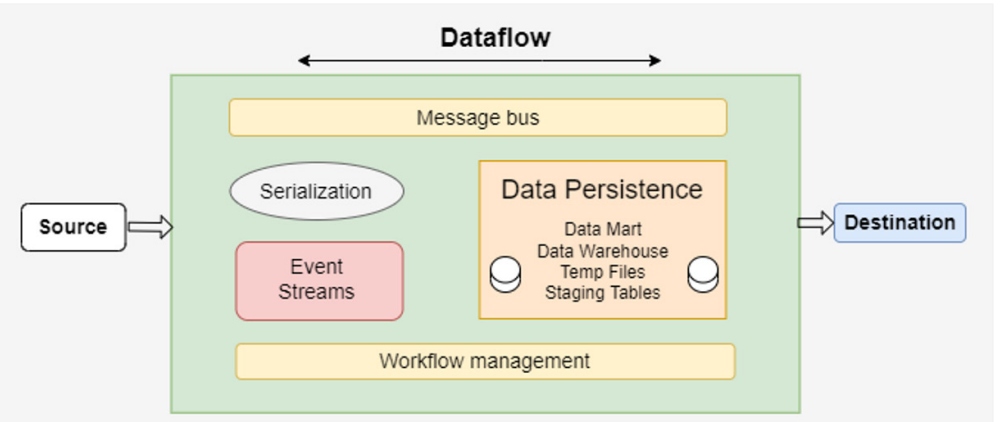
Best Practices for Implementing a Data Pipeline
To build effective pipelines, recommended practices for teams include enabling the execution of concurrent workloads, using extensible tools with inbuilt connectivity, investing in appropriate data wrangling tools, and enforcing data cataloging and ownership.
Enable the Execution of Concurrent Workloads
Most big data applications are required to run multiple data analysis tasks simultaneously. A modern data pipeline should be built with an elastic, multi-cluster, and shared architecture that can handle multiple data flows concurrently. A well-architected pipeline should load and process data from all data flows, which downstream DataOps teams can analyze for further use.
Use Extensible Tools With Inbuilt Connectivity
Modern pipelines are built on multitudes of frameworks and tools that communicate and interact with each other. Tools with inbuilt integration should be utilized to reduce the time, labor, and cost to build connections between various subsystems in the pipeline.
Invest in Appropriate Data Wrangling Tools
Because inconsistencies often lead to poor data quality, it is recommended that the pipeline leverages appropriate data wrangling tools to fix inconsistencies in distinct data entities. With cleaner data, DataOps teams can gather accurate insights for effective decision-making.
Enforce Data Cataloging and Ownership
It is important to keep a log of the data source, the business process owning the dataset, and the user or process accessing those datasets. This offers comprehensive visibility of the datasets that are safe to be used, enforcing trust in data quality and veracity. Cataloging also traces the data lineage, making it easy to establish the path of data flow across the pipeline.
Conclusion
Gartner predicts that the significance of automation will continue to rise to the extent that, "By 2025, more than 90% of enterprises will have an automation architect." Additionally, Gartner projected that, "by 2024, organizations will lower operational costs by 30% by combining hyperautomation technologies with redesigned operational processes."
This is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments