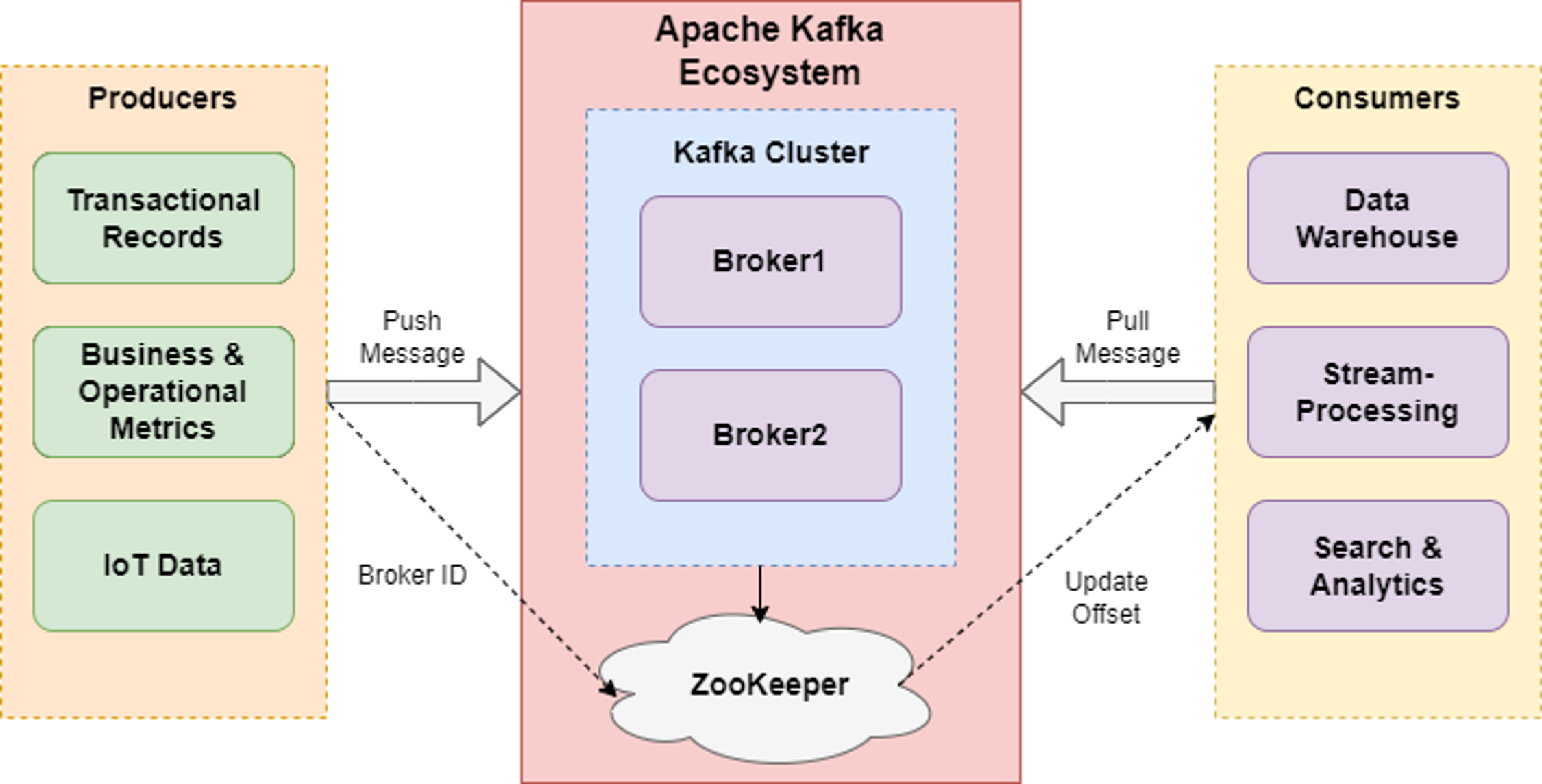
Apache Kafka runs in distributed clusters, with each cluster node being referred to as a Broker. Kafka Connect integrates Kafka instances on Brokers with producers and consumers — clients that produce and consume event data, respectively. All these components rely on the publish-subscribe durable messaging ecosystem to enable instant exchange of event data between servers, processes, and applications.
Pub/Sub in Apache Kafka
The first component in Kafka deals with the production and consumption of the data. The following table describes a few key concepts in Kafka:
Topic |
Defines a logical name for producing and consuming records |
Partition |
Defines a non-overlapping subset of records within a topic |
Offset |
A unique sequential number assigned to each record within a topic partition |
Record |
Contains a key, value, timestamp, and list of headers |
Broker |
Server where records are stored; multiple brokers can be used to form a cluster |
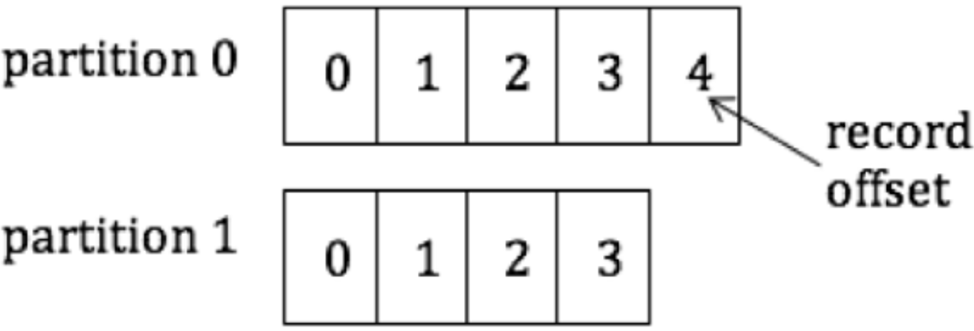
Figure 2 depicts a topic with two partitions. Partition 0 has 5 records, with offsets from 0 to 4, and partition 1 has 4 records, with offsets from 0 to 3.
Figure 2: Partitions in a topic
The following code snippet shows how to produce records to the topic, "test", using the Java API:
Properties props = new Properties();
props.put(“bootstrap.servers”,
“localhost:9092”);
props.put(“key.serializer”,
“org.apache.kafka.common.serialization.StringSerializer”);
props.put(“value.serializer”,
“org.apache.kafka.common.serialization.StringSerializer”);
Producer<String, String> producer = new
KafkaProducer<>(props);
producer.send(
new ProducerRecord<String, String>(“test”, “key”, “value”));
In the example above, both the key and value are strings, so we are using a StringSerializer. It’s possible to customize the serializer when types become more complex. The following code snippet shows how to consume records with key and value strings in Java:
Properties props = new Properties(); props.put(“bootstrap.servers”, “localhost:9092”);
props.put(“key.deserializer”,
“org.apache.kafka.common.serialization.StringDeserializer”);
props.put(“value.deserializer”,
“org.apache.kafka.common.serialization.StringDeserializer”);
KafkaConsumer<String, String> consumer =
new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(“test”));
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf(“offset=%d, key=%s, value=%s”,
record.offset(), record.key(), record.value());
consumer.commitSync();
}
Records within a partition are always delivered to the consumer in offset order. By saving the offset of the last consumed record from each partition, the consumer can resume from where it left off after a restart. In the example above, we use the commitSync() API to save the offsets explicitly after consuming a batch of records. Users can also save the offsets automatically by setting the property, enable.auto.commit, to true.
A record in Kafka is not removed from the broker immediately after it is consumed. Instead, it is retained according to a configured retention policy. The following are two common retention policies:
log.retention.hours – number of hours to keep a record on the brokerlog.retention.bytes – maximum size of records retained in a partition
Kafka Connect
The second component is Kafka Connect, which is a framework that makes it easy to stream data between Kafka and other systems. Users can deploy a Connect cluster and run various connectors to import data from different sources into Kafka (through Source Connectors) and export data from Kafka further (through Sink Connectors) to storage platforms such as HDFS, S3, or Elasticsearch.
The benefits of using Kafka Connect are:
- Parallelism and fault tolerance
- Avoidance of ad hoc code by reusing existing connectors
- Built-in offset and configuration management
Quick Start for Kafka Connect
The following steps show how to run the existing file connector in standalone mode to copy the content from a source file to a destination file via Kafka:
- Prepare some data in a source file:
> echo -e \”hello\nworld\” > test.txt
- Start a file source and a file sink connector:
> bin/connect-standalone.sh
config/connect-file-source.properties
config/connect-file-sink.properties
- Verify the data in the destination file:
> more test.sink.txt
hello
- Verify the data in Kafka:
> bin/kafka-console-consumer.sh
--bootstrap-server localhost:9092
--topic connect-test
--from-beginning
{“schema”:{“type”:”string”,
“optional”:false},
“payload”:”hello”}
{“schema”:{“type”:”string”,
“optional”:false},
“payload”:”world”}
In the example above, the data in the source file, test.txt, is first streamed into a Kafka topic, connect-test, through a file source connector. The records in connect-test are then streamed into the destination file, test.sink.txt. If a new line is added to test.txt, it will show up immediately in test.sink.txt. Note that we achieve this by running two connectors without writing any custom code.
Connectors are powerful tools that allow for integration of Apache Kafka into many other systems. There are many open-source and commercially supported options for integrating Apache Kafka — both at the connector layer as well as through an integration services layer — that can provide much more flexibility in message transformation.
Transformations in Connect
Connect is primarily designed to stream data between systems as-is, whereas Kafka Streams is designed to perform complex transformations once the data is in Kafka. That said, Kafka Connect provides a mechanism used to perform simple transformations per record. The following example shows how to enable a couple of transformations in the file source connector:
- Add the following lines to
connect-file-source.properties:
transforms=MakeMap, InsertSource
transforms.MakeMap.type=org.apache.kafka
.connect.transforms.HoistField$Value
transforms.MakeMap.field=line
transforms.InsertSource.type=org.apache
.kafka.connect.transforms
.InsertField$Value
transforms.InsertSource.static.field=
data_source
transforms.InsertSource.static.value=
test-file-source
- Start a file source connector:
> bin/connect-standalone.sh
config/connect-file-source.properties
- Verify the data in Kafka:
> bin/kafka-console-consumer.sh
--bootstrap-server localhost:9092
--topic connect-test
{“line”:”hello”,”data_source”:”test
-file-source”}
{“line”:”world”,”data_source”:”test
-file-source”}
In step one above, we add two transformations, MakeMap and InsertSource, which are implemented by the classes, HoistField$Value and InsertField$Value, respectively. The first one adds a field name, line, to each input string. The second one adds an additional field, data_source, that indicates the name of the source file. After applying the transformation logic, the data in the input file is now transformed to the output in step three. Because the last transformation step is more complex, we implement it with the Streams API (covered in more detail below):
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
StreamsBuilder builder = new StreamsBuilder();
// build a stream from an input topic
KStream<String, String> source = builder.stream(
“streams-plaintext-input”,
Consumed.with(stringSerde, stringSerde));
KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split(“ “)))
.groupBy((key, value) -> value)
.count();
// convert the output to another topic
counts.toStream().to(“streams-wordcount-output”,
Produced.with(stringSerde, longSerde));
Connect REST API
In production, Kafka Connect usually runs in distributed mode and can be managed through REST APIs. The following table lists the common APIs. See the Apache Kafka documentation for more information.
| Connect REST API |
Action |
GET /connectors
|
Return a list of active connectors |
POST /connectors
|
Create a new connector |
GET /connectors/{name}
|
Get information for the connector |
GET /connectors/{name} /config
|
Get configuration parameters for the connector |
PUT /connectors/{name} /config
|
Update configuration parameters for the connector |
GET /connectors/{name} /status
|
Get the current status of the connector |
Kafka Streams
Kafka Streams is a client library for building real-time applications and microservices where the input and/or output data is stored in Kafka. The benefits of using Kafka Streams are:
- Less code in the application
- Built-in state management
- Lightweight
- Parallelism and fault tolerance
The most common way of using Kafka Streams is through the Streams DSL, which includes operations such as filtering, joining, grouping, and aggregation. The following code snippet shows the main logic of a Streams example called WordCountDemo:
final Serde stringSerde = Serdes.String();
final Serde longSerde = Serdes.Long();
StreamsBuilder builder = new StreamsBuilder();
// build a stream from an input topic
KStream source = builder.stream(
“streams-plaintext-input”,
Consumed.with(stringSerde, stringSerde));
KTable counts = source
.flatMapValues(value -\> Arrays.asList(value.
toLowerCase().split(“ “)))
.groupBy((key, value) -\> value) .count();
// convert the output to another topic
counts.toStream().to(“streams-wordcount-output”,
Produced.with(stringSerde, longSerde));
The code above first creates a stream from an input topic, streams-plaintext-input. It then applies a transformation to split each input line into words. Next, it counts the number of occurrences of each unique word. Finally, the results are written to an output topic, streams-wordcount-output.
The following are steps to run the example code:
- Create the input topic:
bin/kafka-topics.sh --create
--zookeeper localhost:2181
--replication-factor 1
--partitions 1
--topic streams-plaintext-input
- Run the stream application:
bin/kafka-run-class.sh org.apache.
kafka.streams.examples.wordcount.
WordCountDemo
- Produce some data in the input topic:
bin/kafka-console-producer.sh
--broker-list localhost:9092
--topic streams-plaintext-input
hello world
- Verify the data in the output topic:
bin/kafka-console-consumer.sh
--bootstrap-server localhost:9092
--topic streams-wordcount-output
--from-beginning
--formatter kafka.tools.
DefaultMessageFormatter
--property print.key=true
--property print.value=true
--property key.deserializer=
org.apache.kafka.common.
serialization.StringDeserializer
--property value.deserializer=
org.apache.kafka.common.
serialization.LongDeserializer
hello 1
world 1
KStream vs. KTable
There are two key concepts in Kafka Streams: KStream and KTable. A topic can be viewed as either of the two. Their differences are summarized in the table below:
|
KStream |
KTable |
Concept |
Each record is treated as an append to the stream. |
Each record is treated as an update to an existing key. |
Usage |
Model append-only data (e.g., click streams). |
Model updatable reference data (e.g., user profiles). |
The following example illustrates their differences:
(Key, Value) Records |
Sum of Values as KStream |
Sum of Values as KTable |
(“k1”, 2) (“k1”, 5)
|
7
|
5
|
When a topic is viewed as a KStream, there are two independent records and, thus, the sum of the values is 7. On the other hand, if the topic is viewed as a KTable, the second record is treated as an update to the first record since they have the same key: “k1”. Therefore, only the second record is retained in the stream, and the sum is 5 instead.
KStreams DSL
The following section outlines a list of common operations available in Kafka Streams.
KStream operators help abstract each record stream into independent key-value pairs. Such operations include:
filter(Predicate) – Create a new KStream that consists of all records of this stream that satisfy the given predicate.
Example:
ks_out = ks_in.filter( (key, value) -> value > 5 );
ks_in: ks_out: (“k1”, 2) (“k2”, 7) (“k2”, 7)
map(KeyValueMapper) – Transform each record of the input stream into a new record in the output stream (both key and value type can be altered arbitrarily).
Example:
ks_out = ks_in..map( (key, value) -> new KeyValue<>(key, key) )
ks_in: ks_out: (“k1”, 2) (“k1”, “k1”) (“k2”, 7) (“k2”, “k2”)
groupBy() – Group the records by their current key into a KGroupedStream while preserving the original values.
Example:
ks_out = ks.groupBy()
ks_in: ks_out: (“k1”, 1) (“k1”, ((“k1”, 1), (“k2”, 2) (“k1”, 3))) (“k1”, 3) (“k2”, ((“k2”, 2)))
join(KTable, ValueJoiner) – Join records of the input stream with records from the KTable if the keys from the records match. Return a stream of the key and the combined value using ValueJoiner.
Example:
ks_out = ks_in.join( kt, (value1, value2) -> value1 + value2 );
ks_in: kt: (“k1”, 1) (“k1”, 11) (“k2”, 2) (“k2”, 12) (“k3”, 3) (“k4”, 13)
ks_out: (“k1”, 12) (“k2”, 14)
join(KStream, ValueJoiner, JoinWindows) – Join records of the two streams if the keys match and the timestamp from the records satisfy the time constraint specified by JoinWindows. Return a stream of the key and the combined value using ValueJoiner.
Example:
ks_out = ks1.join( ks2, (value1, value2) -> value1 + value2, JoinWindows. of(100) );
ks1: ks2: (“k1”, 1, 100t) (“k1”, 11, 150t) (“k2”, 2, 200t) (“k2”, 12, 350t) (“k3”, 3, 300t) (“k4”, 13, 380t) * t indicates a timestamp.
ks_out: (“k1”, 12)
KGroupedStream operators, unlike KStream operators, help abstract grouped streams of key-value pairs. Such operations include:
count() – Count the number of records in this stream by the grouped key and return it as a KTable.
Example:
kt = kgs.count(); kgs: (“k1”, ((“k1”, 1), (“k1”, 3))) (“k2”, ((“k2”, 2)))
kt: (“k1”, 2) (“k2”, 1)
reduce(Reducer) – Combine the values of records in this stream by the grouped key and return it as a KTable.
Example:
kt = kgs.reduce( (aggValue, newValue) -> aggValue + newValue );
kgs: (“k1”, (“k1”, 1), (“k1”, 3))) (“k2”, ((“k2”, 2)))
kt: (“k1”, 4) (“k2”, 2)
windowedBy(Windows) – Further group the records by the timestamp and return it as a TimeWindowedKStream.
Example:
twks = kgs.windowedBy( TimeWindows.
of(100) );
kgs: (“k1”, ((“k1”, 1, 100t), (“k1”, 3, 150t))) (“k2”, ((“k2”, 2, 100t), (“k2”, 4, 250t))) * t indicates a timestamp.
twks: (“k1”, 100t -- 200t, ((“k1”, 1, 100t), (“k1”, 3, 150t))) (“k2”, 100t -- 200t, ((“k2”, 2, 100t))) (“k2”, 200t -- 300t, ((“k2”, 4, 250t)))
Additional details on the respective set of operations on KTable and KGroupedTable can be found in the Kafka Documentation.
Querying States in KStreams
While processing data in real time, a KStreams application locally maintains states such as the word counts in the previous example. Those states can be queried interactively through an API described in the Interactive Queries section of the Kafka documentation. This avoids the need of an external data store for exporting and serving those states.
Exactly-Once Processing in KStreams
Failures in the brokers or the clients may introduce duplicates during the processing of records. KStreams provides the capability of processing records exactly once, even under failures. This can be achieved by simply setting the property, processing.guarantee, to exactly_once in KStreams.
Documenting and Visualizing Data Streams
Processing stream data involves correlating data between streams, analyzing patterns, and understanding application/user behavior to make predictions. In a typical event stream, events are continuously flowing through Apache Kafka clusters, with a rich ecosystem of clients and data sinks integrating with the library. Making real-time decisions from data streams, therefore, requires the enforcement of comprehensive observability, event ownership, and governance.
Governing data in motion is often a shared responsibility between developers, DataOps, and business development teams. This often starts with business managers defining the business and technical requirements for event management, while data engineers are managing client permissions for creating internal topics. Subsequently, developers/system admins configure security settings within the clients and then administer each client’s corresponding settings within Kafka Streams.
Although Kafka lacks an innate event portal to catalog event streams and visualize the topology of the data pipelines, the Kafka streaming client library supports a data lineage visibility to identify the origin and path taken by an event. It is possible to extend Kafka by integrating it with an event management platform that can enforce the discovery, visualization, and cataloging of event streams. Such platforms identify newer data schemas, connectors, client groups, and events as they occur, which streamlines the recording of event changes. These tools help uncover deeper analytical insights and help solve complex data relationships while also fostering efficient collaboration among distributed teams.

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}