Data Governance: Data Architecture (Part 2)
This article discusses data governance and data architecture, and the top three data architecture types that are most frequently used.
Join the DZone community and get the full member experience.
Join For FreeData governance is a framework created by the collaboration of people with various roles and responsibilities working towards establishing the processes, policies, standards, and metrics to achieve the organization’s goals. These goals can range from providing trusted data for businesses to developing accurate analytics for evaluating business performance, complying with regulatory compliances, protecting the data, ensuring data privacy, and enabling the data management life cycle.
The important areas of data governance are described below.

What Is Data Architecture?
Data Architecture is a fundamental pillar in an organization, and it presents the blueprint of an integrated view comprising the different data governance disciplines shown in the above diagram.
Data Architecture depicts the business's overall strategy in the form of a design. It highlights the requirements for the strategy, such as data sources and various data points. Data Architecture helps to demonstrate how data integration should occur from different data sets that come from different source systems.
Data Architecture shows the integrated view of different levels of data abstractions such as raw data, curated data, mastered data, and aggregated data for business analytics.
The data architecture also explains how data is being managed. This can include how the data is acquired, stored, secured, processed, archived, and deleted.
Data Architecture Types
There are multiple types of data architectures, and the appropriate model can be chosen based on several parameters such as cost, performance, reliability, and availability. The most prominent data architecture models being used in the industry are:
- Centralized Data Architecture
- Distributed Architecture
- Data Lake Architecture
- Lakehouse Architecture
- Event-Driven Architecture
- Federated Architecture
- Microservice Architecture
- Hybrid Architecture
- Data Fabric Architecture
- Data Mesh Architecture
We will cover the top three architectures which are prominently used.
Centralized Data Architecture
In this type of architecture, the data is stored in a centralized place, such as a centralized data warehouse, where all the source systems are integrated. From there, data access is provided per the established policies and access controls. In the below picture, the centralized data model is populated with data from different locations in an integrated fashion.
Some of the advantages of using this architecture model are:
- Data is available at a single location, making accessing and coordinating data easier.
- This method will have less data redundancy as compared to other methods since all the data is stored in a single place.
- The cost of implementation is economical in comparison with other architectures.
- Data consistency, transformation, security, etc., is much easier to implement
Some of the disadvantages are:
- If there are many data consumers, this model can lead to data traffic that may result in performance issues.
- If a system failure occurs in the centralized system, then the entire system will have an impact
- There may be regulatory or specific restrictions on sharing the data with other locations
Distributed Architecture
In the distributed architecture, the centralized data will be stored in multiple locations, and the systems closer to that location will perform well. Data replications are generally performed to maintain data consistency and accuracy in this type of architecture. In the picture below, the standard data model has been replicated in three locations, and the data is ingested and consumed close to the respective locations. The data from these three locations have been synchronized to keep them available in all the locations.

The advantages and disadvantages are similar to the Centralized Data Architecture model because both these models rely heavily on a centralized approach.
Some of the advantages are:
- Data is available at a single location, making accessing and coordinating data easier.
- This method will have less data redundancy compared to other methods since all the data is stored in a single place.
- The cost of implementation is economical in comparison with other architectures.
- Data consistency, transformation, security, etc., is much easier to implement
Disadvantages:
- There is higher data traffic when considering the centralized database.
- If a system failure occurs in the centralized system, then the entire system will have the impact
- We cannot use this model If there are any regulatory or specific restrictions on sharing the data with other countries
Data Lake Architecture
In the data lake architecture, all the data sources are stored in a location in their original raw data format. This model typically helps data scientists and analysts explore the hidden data points, and it allows for flexibility in designing different ML models and analytics. This architecture is generally deployed in the cloud storage services such as S3, Azure BLOB, and Cloud storage facilitated by cloud service providers such as AWS, Azure, GCP, and others.
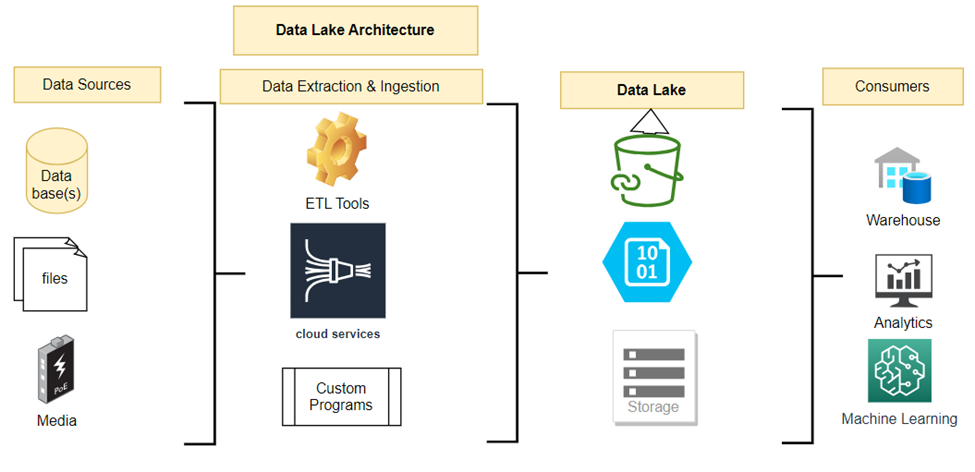
Advantages:
- Data lake architecture allows for storing different data types, such as structured, semi-structured, and unstructured data
- This model allows the storage of original raw data to perform data explorations and machine learning
- This architecture is scalable and can store a very large set of data
- The data storage and computing are de-coupled in this architecture due to the ease of scaling these two components.
- The scalability allows for it to be a cost-effective solution architecture
- This architecture supports advanced analytics, such as machine learning
Disadvantages:
- If there is no proper governance, this model may lead to data silos
- Data lakes are prone to data security and privacy threats
- Data ingestion, curation, and enforcing the schema is complex within this model
Conclusion
The key takeaways from this article are:
- A robust data governance framework is needed when integrating data from various source systems
- A centralized data architecture utilizes a centralized place to integrate different source systems
- A distributed data architecture model utilizes a centralized mechanism in different locations. It differs from a centralized data architecture model because there are several locations where the data is stored in this model.
- A data lake architecture model allows for data to be stored in its original raw format and aids in data exploration.
Opinions expressed by DZone contributors are their own.
Comments