Decoupling Storage and Compute: Have We Gone Too Far?
The latest innovations in the data engineering industry revolve around how different data platforms are coupling or decoupling storage and compute. Is it too much?
Join the DZone community and get the full member experience.
Join For FreeData engineers discovered the benefits of conscious uncoupling around the same time as Gwyneth Paltrow and Chris Martin in 2014.
Of course, instead of life partners, engineers were starting to gleefully decouple storage and compute with emerging technologies like Snowflake (2012), Databricks (2013), and BigQuery (2010).
This had amazing advantages from both a cost and scale perspective compared to on-premises databases. A data engineering manager at a Fortune 500 company expressed the pain of on-prem limitations to me by saying:
“Our analysts were unable to run the queries they wanted to run when they wanted to run them. Our data warehouse would be down for 12 hours a day because we would regularly need to take it offline for data transformations and loading…The only word I can use to describe this process is painful.”
A decade later, a considerable amount of innovation in the data management industry is revolving around how different data platforms are coupling or decoupling storage and compute (don’t worry I include examples in the next section). Closely related to this is how those same platforms are bundling or unbundling related data services from data ingestion and transformation to data governance and monitoring.
Why are these things related, and more importantly, why should data leaders care?
Well, the connective tissue that powers and integrates these services is frequently found in the metadata of table formats (storage) and query/job logs (compute). How these aspects are managed within your data platform will play an outsized role in its performance, cost, ease of use, partner ecosystem, and future viability.
Asking what type of data platform and what level of decoupling is correct is like asking what is the right way to format your SQL code: It is largely going to depend on personal preferences and professional requirements; however, there is a small range of possibilities that will satisfy most.
I believe — at this current moment — that range for data platforms follows Aristotle’s golden mean. The majority will be best served by options in the middle of the spectrum, while operating at either extreme will be for the select few with very specialized use cases.
Let’s dive into the current landscape and recent evolutions before looking closer at why that may be the case.
The Storage and Compute Data Platform Spectrum
A loud few have made headlines with a “cloud is expensive let’s go back to our server racks” movement. While that may be a legitimate strategy for some, it is a rapidly dwindling minority.
Just last week, the Pragmatic Engineer shone a spotlight on Twitter’s rate throttling and significant user experience issues that likely resulted from their moving machine learning models off of GCP and relying exclusively on their three data centers.
The ability to scale and consume storage and compute independently is much more cost effective and performative, but having these separate functions within the same data platform has advantages as well.
The average unoptimized SQL query executed as part of an ad hoc analytics request will typically run a lot faster in these platforms that have been tuned to work well out of the box. A more decoupled architecture that separates compute and storage at the platform level can be very cost effective in running heavy workloads, but that assumes a highly trained staff spends the time optimizing those workloads.
Data platforms with combined but decoupled storage and compute also provide a more robust, integrated user experience across several key DataOps tasks. Take data governance, for example. These platforms provide a centralized mechanism to do access control, whereas decoupled architectures require federating roles across multiple query engines — a non-trivial task.
The decoupled but combined approach is the magic that made one of the most common reviews of Snowflake that “Everything just works.” It’s no wonder Snowflake recently doubled down with Unistore for transactional workloads and opened up Snowpark to support Python and more data science (compute) workloads.
Databricks saw amazing growth with its focus on its Spark processing framework, but it’s also not a coincidence that it unlocked a new level of growth after adding metadata and ACID-like transactions within Delta tables and governance features within Unity Catalog. They also recently doubled down and made it so when you write to a Delta table (storage) the metadata within that table is written in formats readable by Delta, Apache, and Hudi.
Challengers' Platforms
This is why it’s interesting to see that many of the latest emerging data engineering technologies are starting to separate storage and compute at the vendor level. For example, Tabular describes itself as a “headless data warehouse” or “everything you need in a data warehouse except compute.”
Going a step further, some organizations are migrating to Apache Iceberg tables within a data lake with “do it yourself” management of backend infrastructure and using a separate query engine like Trino. This is most commonly due to customer-facing use cases that require highly performant and cost-effective, interactive queries.
DuckDB combines storage and compute, but sacrifices the near infinite compute of the modern data stack, in favor of developer simplicity and reduced cost.
So the question remains, are these innovations likely to replace incumbent cloud native data platforms?
Again, that answer will depend on who you are. DuckDB is an incredibly popular tool that many data analysts love, but it’s probably not going to be the rock upon which you build your data platform. Ultimately, we are seeing, and I believe will continue to see a distribution that looks like this:
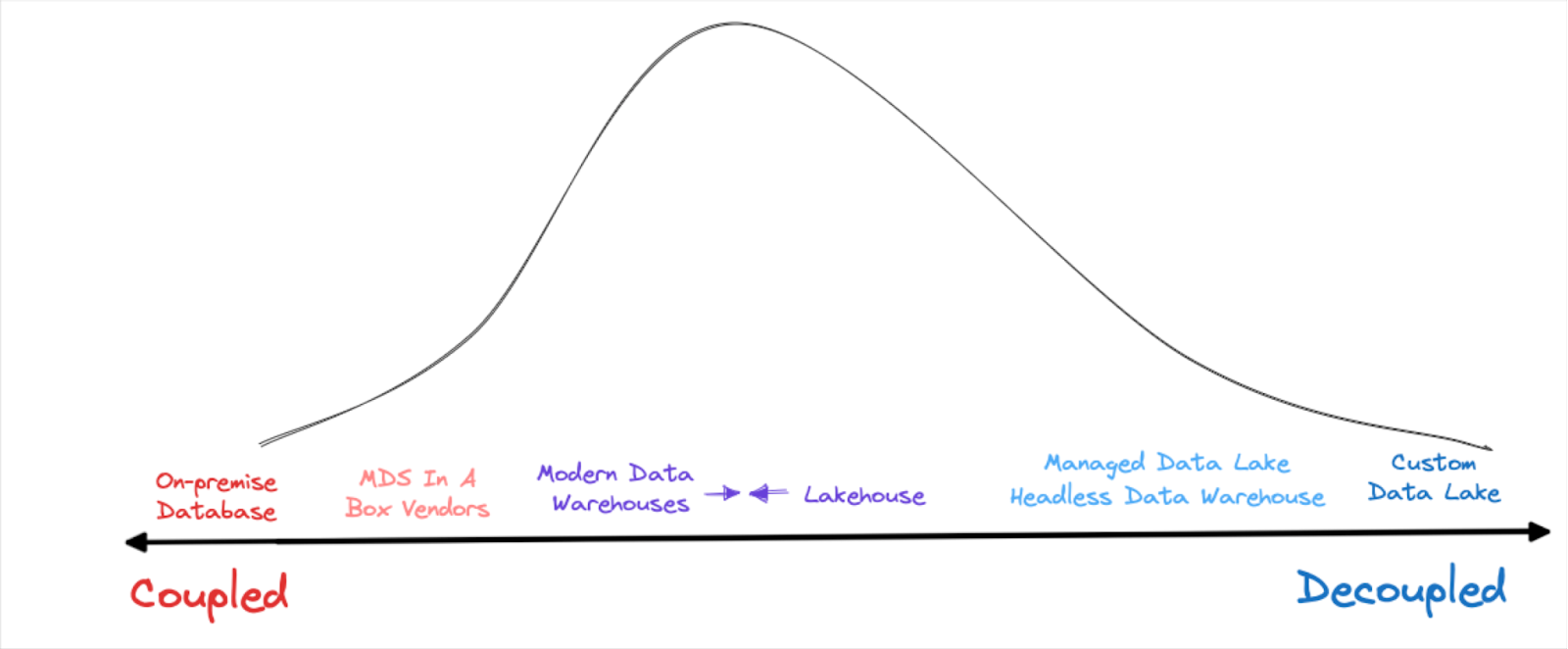
I’ll explain why by looking across the modern data stack and data platform types across a couple of key dimensions.
Degree and Purpose of Consolidation
B2B vendors reverently reference the “single pane of glass” all the time. Is there value in having multiple services under a single umbrella? It depends on the quality of each service and how it corresponds to your needs.
The value in the single pane of glass really comes from unifying what would otherwise be siloed information into a single story, or separate actions into what should be a single workflow. Let’s use Microsoft 365 as an example of this concept.
It’s valuable having video and email integrated within their Teams collaboration application as those are core aspects of the meeting scheduling and video conferencing process. Is it as valuable to have Sway within their suite of apps? Again, it goes back to your requirements for interactive reporting.
Coming back to the data universe, compute and storage are vital to that single story (the who, what, when, where, why, how of DataOps) and key workflows for aspects like: cost, quality, and access management. For this reason, these platforms will have the most robust partner ecosystems and more seamless integrations. This will likely be a key criterion for you unless you are the type of person who was using Windows and Fire phones rather than iPhones and Androids.
Adam Woods, CEO of Choozle, spoke to our team last year about the importance he places on having a robust and tightly integrated partner ecosystem surround his data platform.
“I love that…my data stack is always up-to-date and I never have to apply a patch. We are able to reinvest the time developers and database analysts would have spent worrying about updates and infrastructure into building exceptional customer experiences,” he said.
Of course, there are always exceptions to the rule. A true data lake, headless warehouse, or other more complex platform may be ideal if you have edge cases at a large scale.
Should your semantic layer, data quality, access control, catalog, BI, transformation, ingestion, and other tools all be bundled within the same platform? I think there are valid perspectives across this spectrum, but like every other department, most data teams will have a collection of tools that best fit their requirements.
Takeaway
- Most data leaders will want to prioritize using a data platform that has both compute and storage services that can facilitate a “single story” and support a diverse partner ecosystem.
Performance vs. Ease of Use
Generally speaking, the more customizable a platform, the better it can perform across a wide array of use cases…and the harder it is to use. This is a pretty inescapable tradeoff and one you are making when you separate the storage and compute services across vendors.
When thinking about data platform “ease of use,” it’s helpful to consider not only the day-to-day usage of the platform but the simplicity of administration and customization as well.
In my experience, many teams overfit for platform performance. Our technical backgrounds immediately start comparing platforms like they are cars: “What’s the horsepower for this workload? What about that workload?”
Don’t get me wrong, an optimized data platform can translate into millions of annual savings. It’s important. But, if you are hiring extra engineers to manage S3 configurations or you need to launch a multi-month project every quarter to onboard new aspects of the business onto your data platform, that has a high cost as well.
You see this same decision making paradigm playout with open-source solutions. The upfront cost is negligible, but the time cost of maintaining the infrastructure can be substantial.
Solution costs and engineering salary costs are not the same, and this false equivalency can create issues down the road. There are two reasons why:
- Assuming your usage remains static (an important caveat), your solution costs generally stay the same while efficiency goes up. That’s because SaaS vendors are constantly shipping new features. On the other hand, the efficiency of a more manual implementation will decline over time as key players leave and new team members need to be onboarded.
- When you spend most of your time maintaining infrastructure, your data team starts to lose the plot. The goal slowly drifts from maximizing business value to maintaining infrastructure at peak performance. More meetings become about infrastructure. Niche infrastructure skills take on an outsized importance and these specialists become more prominent within the organization. Organizational culture matters and it is often shaped by the primary tasks and problems the team is solving.
This second point was a particular emphasis for Michael Sheldon, head of data at Swimply.
“Because we had this mandate as a data team to support the entire company, we needed a data stack that could solve two central issues,” Michael said. “One, to centralize all of the data from all of the different parts of the company in one stable place that everyone could use and refer to as a source of truth. And two, to enable us to have enough time to really focus on the insights and not just the data infrastructure itself.”
Of course, there will be times when your business use case calls for premium performance.
A credit card fraud data product with high latency is just a waste of time. A customer-facing app that gives users the spinning wheel of death will be unacceptable, likely requiring you to deploy a high-performing query engine. However in most cases, your data warehouse or managed data lakehouse will scale just fine. Double-check any requirements that say otherwise.
Takeaway
- While ease of use and performance are interrelated variables that must be balanced, most data leaders will want to have a bias towards ease of use due to relatively hidden maintenance and culture costs. Your competitive advantage is more frequently found in enriching and applying first-party data rather than maintaining complex infrastructure.
In Defense of the MDS
I know it’s fashionable to bash the modern data stack (and you might not need it), but for all its faults, it will be the best choice for the majority of data teams. It’s an ideal blend of quick value generation and future proofing a long-term investment.
Many of the emerging technologies have significant value albeit with more narrow use cases. It will be exciting to see how they evolve and shape the practice of data engineering.
However, while compute and storage need to operate and scale separately, having those services and corresponding metadata within the same platform is just too powerful with too many advantages to ignore.
Published at DZone with permission of Shane Murray. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments