Designing Databases for Distributed Systems
Several data management patterns have emerged for microservices and cloud-native solutions. Learn important patterns to manage data in a distributed environment.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2023 Database Systems Trend Report.
For more:
Read the Report
Database design is a critical factor in microservices and cloud-native solutions because a microservices-based architecture results in distributed data. Instead of data management happening in a single process, multiple processes can manipulate the data. The rise of cloud computing has made data even more distributed.
To deal with this complexity, several data management patterns have emerged for microservices and cloud-native solutions. In this article, we will look at the most important patterns that can help us manage data in a distributed environment.
The Challenges of Database Design for Microservices and the Cloud
Before we dig into the specific data management patterns, it is important to understand the key challenges with database design for microservices and the cloud:
- In a microservices architecture, data is distributed across different nodes. Some of these nodes can be in different data centers in completely different geographic regions of the world. In this situation, it is tough to guarantee consistency of data across all the nodes. At any given point in time, there can be differences in the state of data between various nodes. This is also known as the problem of eventual consistency.
- Since the data is distributed, there's no central authority that manages data like in single-node monolithic systems. It's important for the various participating systems to use a mechanism (e.g., consensus algorithms) for data management.
- The attack surface for malicious actors is larger in a microservices architecture since there are multiple moving parts. This means we need to establish a more robust security posture while building microservices.
- The main promise of microservices and the cloud is scalability. While it becomes easier to scale the application processes, it is not so easy to scale the database nodes horizontally. Without proper scalability, databases can turn into performance bottlenecks.
Diving Into Data Management Patterns
Considering the associated challenges, several patterns are available to manage data in microservices and cloud-native applications. The main job of these patterns is to facilitate the developers in addressing the various challenges mentioned above. Let's look at each of these patterns one by one.
Database per Service
As the name suggests, this pattern proposes that each microservices manages its own data. This implies that no other microservices can directly access or manipulate the data managed by another microservice. Any exchange or manipulation of data can be done only by using a set of well-defined APIs. The figure below shows an example of a database-per-service pattern.

Figure 1: Database-per-service pattern
At face value, this pattern seems quite simple. It can be implemented relatively easily when we are starting with a brand-new application. However, when we are migrating an existing monolithic application to a microservices architecture, the demarcation between services is not so clear.
Most of the functionality is written in a way where different parts of the system access data from other parts informally.
Two main areas that we need to focus on when using a database-per-service pattern:
- Defining bounded contexts for each service
- Managing business transactions spanning multiple microservices
Shared Database
The next important pattern is the shared database pattern. Though this pattern supports microservices architecture, it adopts a much more lenient approach by using a shared database accessible to multiple microservices. For existing applications transitioning to a microservices architecture, this is a much safer pattern, as we can slowly evolve the application layer without changing the database design. However, this approach takes away some benefits of microservices:
- Developers across teams need to coordinate schema changes to tables.
- Runtime conflicts may arise when multiple services are trying to access the same database resources.
CQRS and Event Sourcing
In the command query responsibility segregation (CQRS) pattern, an application listens to domain events from other microservices and updates a separate database for supporting views and queries. We can then serve complex aggregation queries from this separate database while optimizing the performance and scaling it up as needed.
Event sourcing takes it a bit further by storing the state of the entity or the aggregate as a sequence of events. Whenever we have an update or an insert on an object, a new event is created and stored in the event store. We can use CQRS and event sourcing together to solve a lot of challenges around event handling and maintaining separate query data. This way, you can scale the writes and reads separately based on their individual requirements.
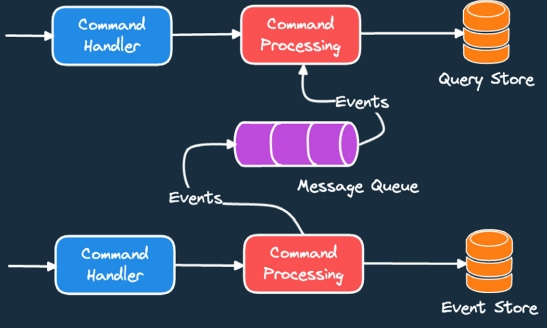
Figure 2: Event sourcing and CQRS in action together
On the downside, this is an unfamiliar style of building applications for most developers, and there are more moving parts to manage.
Saga Pattern
The saga pattern is another solution for handling business transactions across multiple microservices. For example, placing an order on a food delivery app is a business transaction. In the saga pattern, we break this business transaction into a sequence of local transactions handled by different services. For every local transaction, the service that performs the transaction publishes an event.
The event triggers a subsequent transaction in another service, and the chain continues until the entire business transaction is completed. If any particular transaction in the chain fails, the saga rolls back by executing a series of compensating transactions that undo the impact of all the previous transactions.
There are two types of saga implementations:
- Orchestration-based saga
- Choreography-based saga
Sharding
Sharding helps in building cloud-native applications. It involves separating rows of one table into multiple different tables. This is also known as horizontal partitioning, but when the partitions reside on different nodes, they are known as shards. Sharding helps us improve the read and write scalability of the database. Also, it improves the performance of queries because a particular query must deal with fewer records as a result of sharding.
Replication
Replication is a very important data management pattern. It involves creating multiple copies of the database. Each copy is identical and runs on a different server or node. Changes made to one copy are propagated to the other copies. This is known as replication. There are several types of replication approaches, such as:
- Single-leader replication
- Multi-leader replication
- Leaderless replication
Replication helps us achieve high availability and boosts reliability, and it lets us scale out read operations since read requests can be diverted to multiple servers. Figure 3 below shows sharding and replication working in combination.
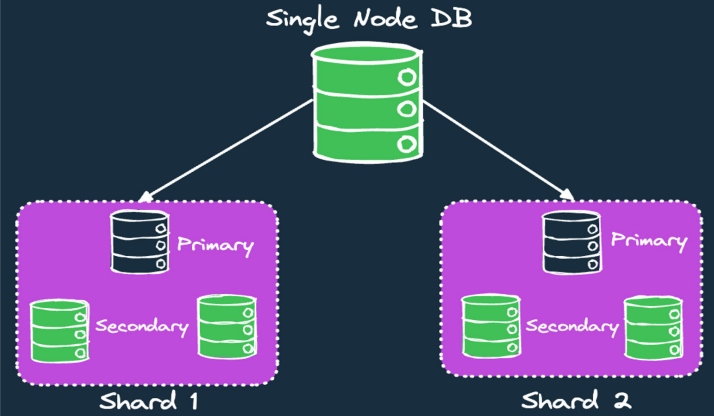
Figure 3: Using sharding and replication together
Best Practices for Database Design in a Cloud-Native Environment
While these patterns can go a long way in addressing data management issues in microservices and cloud-native architecture, we also need to follow some best practices to make life easier.
Here are a few best practices:
- We must try to design a solution for resilience. This is because faults are inevitable in a microservices architecture, and the design should accommodate failures and recover from them without disrupting the business.
- We must implement proper migration strategies when transitioning to one of the patterns. Some of the common strategies that can be evaluated are schema first versus data first, blue-green deployments, or using the strangler pattern.
- Don't ignore backups and well-tested disaster recovery systems. These things are important even for single-node databases. However, in a distributed data management approach, disaster recovery becomes even more important.
- Constant monitoring and observability are equally important in microservices or cloud-native applications. For example, techniques like sharding can lead to unbalanced partitions and hotspots. Without proper monitoring solutions, any reactions to such situations may come too late and may put the business at risk.
Conclusion
We can conclude that good database design is absolutely vital in a microservices and cloud-native environment. Without proper design, an application will face multiple problems due to the inherent complexity of distributed data. Multiple data management patterns exist to help us deal with data in a more reliable and scalable manner. However, each pattern has its own challenges and set of advantages and disadvantages. No pattern fits all the possible scenarios, and we should select a particular pattern only after managing the various trade-offs.
This is an article from DZone's 2023 Database Systems Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments