When deploying a distributed SQL database, there are some key things to consider, including high availability architecture, schema design, indexing, and cross-region replication.
Architecting for Availability
Whether the application is in an on-premises data center or in the public cloud, there are usually multiple availability zones. These may be different racks or a separate nearby data center. It is important to configure the distributed SQL database to be aware of the different zones to ensure that replicas are spread among them. This way, if a zone is lost, then no data is lost.
Some applications require data to be replicated to multiple regions, e.g., data centers that are over 30 miles (48km) away. This requirement may be for disaster recovery and business continuity reasons or because there is data needed in both regions. Some distributed SQL databases support synchronous replication between zones but do so at a high cost of latency and decreased system throughput. Other implementations support asynchronous, or even parallel asynchronous, replication, which keeps up with extreme levels of scale but only offers eventual consistency between regions.
When creating a database, decide how much fault tolerance is required and balance this with performance and cost. It is unlikely that two availability zones or nodes would go out at the same time. However, for some applications, or in some regions, the consequences of this happening are worth the trade-off in performance and cost. There should never be as many replicas as nodes, or the scalability advantage of a distributed SQL database would be lost and have an extreme impact on performance.
All distributed SQL databases require a load balancer of some kind. Some implementations have client-side, driver-based proxies, which get updates from the database and delegate load balancing to the client. Some use simple proxies like HAProxy. Others use smart proxies, which understand the state of the cluster and isolate the client from temporary faults. The advantage of client-side proxies is that they save a hop to a real load balancer. However, they can also expose the client to intermittent network failures and may require more client-side custom error handling code. Overall, a server-side proxy that understands the database will be more foolproof.
Schema Design Issues
For the most part, designing a distributed SQL database schema is the same as creating a schema for any other relational database. There are a few issues to note, most of which are directly related to the distributed nature of the database. First off, having many small tables is rarely ideal in a client-server database, but in a distributed database, they are a bigger issue.
First, using them likely requires numerous joins, which are more costly in a distributed database. Second, keeping them optimally distributed is more overhead. Generally speaking, be more conservative with additional tables in a schema design. It will likely make more sense to have, for example, address line fields in a larger table than to have a separate addresses table.
Autogenerated sequences are often a bottleneck in client-server relational databases, but they are an even bigger problem in a distributed database. For this reason, distributed SQL databases usually recommend UUIDs for autogenerated keys instead of database-generated sequences. When loading a large amount of data for the first time, it may make sense to tell the database how many slices it should start with. If this isn’t done, the database will re-slice and rebalance as the data is loaded. This will take longer and may result in a less optimal distribution of data initially.
Reference data like company locations or a ZIP code table tends to be small and is seldom used outside of being joined with a much larger table. These tables rarely need to scale writes, just reads. Distributed joins that cross multiple nodes are inherently more costly than if all the data is on one node. For this data, it makes sense to have the table placed on all nodes of the database. Write/update performance will be relatively slower (as writes have to be sent to all nodes), but joins against the data will be snappier.
Distributed SQL databases make use of a distribution key for creating a hash and assigning a row to a slice (tablet or partition), which is ultimately assigned to a node. The default on some databases may be the primary key or all fields. Ideally, this should be a column with a reasonable number of distinct values. For instance, if a column can only have the value 0, 1, or 3, then it will be a poor key for a 10-node cluster. A distribution key can be on multiple columns together.
For example, creating a table for blog posts with a distribution key on user_id and date posted:
CREATE TABLE user_posts (
post_id int AUTO_INCREMENT,
user_id int,
posted_on timestamp,
data blob,
PRIMARY KEY (`post_id`) /*$ DISTRIBUTE=1 */,
KEY `user_id_posted_on_idx` (`user_id`,`posted_on`) /*$ DISTRIBUTE=2 */
);
JSON in Distributed SQL
Over the past few years, the growth of NoSQL databases was driven by both the need for scale and flexibility. Feature-rich relational databases were slow to adopt new architectures that scaled out because it was hard to implement their existing feature sets on a distributed back end. Meanwhile, new types of applications, including Internet of Things (IoT), required more flexibility with regard to how data was stored and represented. Relational databases quickly caught up with the need to handle flexible structures, particularly JSON. With distributed SQL, they have also caught up with the need for scale.
Nearly all relational databases handle JSON. The SQL:2016 standard even incorporated JSON into the query language. Distributed SQL databases handle JSON data, but there may be performance or transactional implications compared to tables and rows.
To create a table with a JSON column, use the following statement:
create table files (id int primary key auto_increment, doc json);
Add data to the table as follows:
insert into files (doc) values ('{"foo": {"bar": 1}, "baz": [1,2,3,4]}');
insert into files (doc) values ('{"foo": {"bar": 2}, "baz": [3,4,5]}');
To query the data based on a JSON value, run this query:
select json_extract(doc, '$.baz') from files where json_extract(doc, '$.foo.bar') = 1;
+----------------------------+
| json_extract(doc, '$.baz') |
+----------------------------+
| [1, 2, 3, 4] |
+----------------------------+
1 row in set (0.01 sec)
These are just basic examples; the level of support for JSON varies between distributed SQL databases. Some even offer compatibility features with popular NoSQL databases such as MongoDB.
Columnar Indexes in Distributed SQL
Distributed SQL databases are intended as transactional systems. However, there are a lot of use cases that cross the boundary between transactional and analytical systems. While a distributed SQL database should never be considered as a replacement for a traditional analytical database, there are many cases where real-time information is required. Additionally, it is hard to create a specific index for every type of query, especially on systems that allow ad hoc queries. For this reason, some distributed SQL databases offer columnar indexes in addition to traditional row-based indexes.
Columnar indexes essentially turn the table sideways. Because columns often have a lot of repeated data, this enables higher levels of compression.
Figure 1: Row-oriented vs. column-oriented indexes
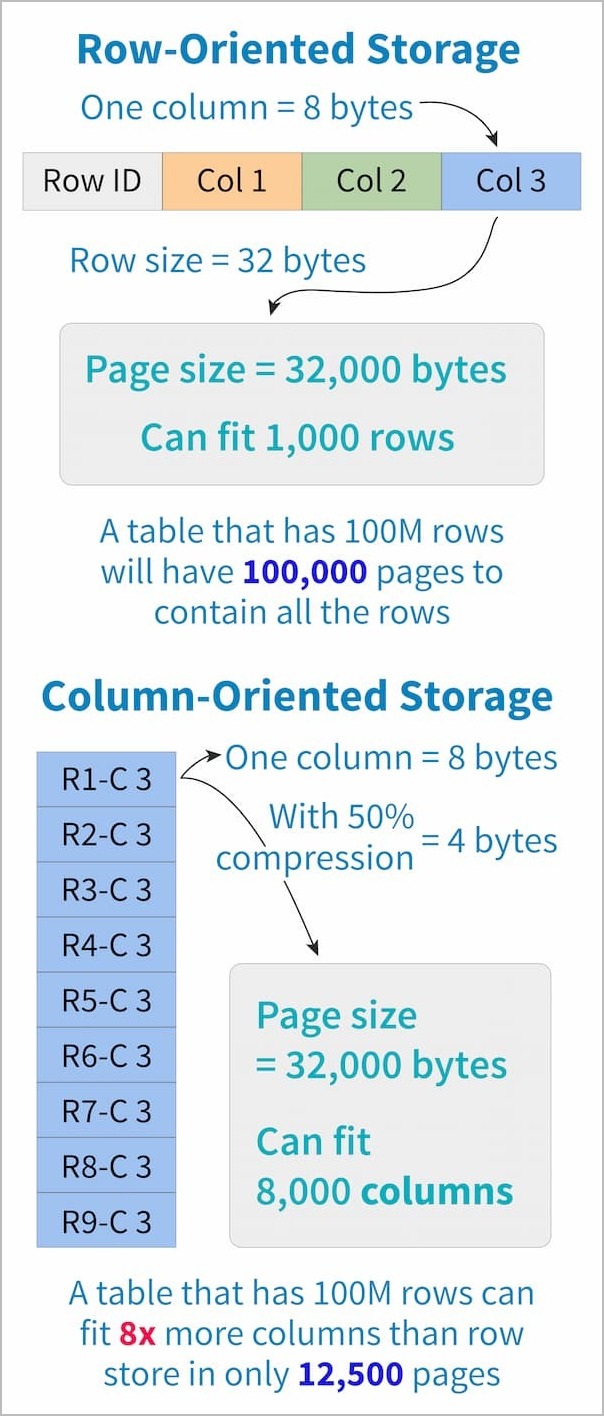
For most OLTP-style queries, a well-targeted row index will outperform columnar indexes, but there are exceptions. First, compression enables range queries to run faster than row indexes. Second, some complex analytical queries have nearly every column from the table in the WHERE clause. Finally, on tables with many indexes, it can be difficult for the optimizer to choose the best index.
A columnar index is a satisfactory index for many use cases such as click-stream data or device data (IoT-type use cases) where range queries are common. They can also be useful for real-time operational and personal analytics where queries are run intraday to understand the current state of the business. They can be used in combination with row indexes, which is especially helpful in the case of queries with a mix of both regular conditionals and ranges.
Not all distributed SQL databases support columnar indexes yet, so make sure that you understand if one is required for your use case before selecting a database.
Cross-Region Replication
Inside a single region or data center, all distributed SQL databases support synchronous replication with transactional consistency. Some distributed SQL databases also support synchronous replication between regions. Other distributed SQL databases support asynchronous replication or parallel asynchronous replication between regions. Each of these options have benefits and drawbacks.
Synchronous replication with transactional consistency between regions ensures availability without data loss — even in the event of a disaster resulting in the complete loss of connectivity to a data center. Theoretically, requests can be balanced or offloaded between different data centers in the event of extraordinary regional traffic.
However, this form of replication comes at a severe cost with regard to write performance and read latency. Every write must be acknowledged by both the local nodes and the cross-region nodes to assure consistency. Locks acquired during commit will affect read performance in both regions, and since the writes last longer, the locks last longer. This type of replication should only be used for specific esoteric use cases.
Asynchronous replication with transactional consistency between regions ensures availability even in the event of data loss. There are different levels that can be configured with regard to acknowledgement. These trade off between performance and potential for error or data loss in the event of the loss of a region. The simplest case is that the message, including the transaction, was prepared on the source region. If the source region is lost before the data is sent, the data could be lost. Another configuration may require a node on the destination to have received the message.
In the latter case, the source could be lost, and the destination would still have the message and eventually commit it. If writes are allowed to both regions in the case of asynchronous replication, the nature of the data or the application must ensure that conflicts are not possible.
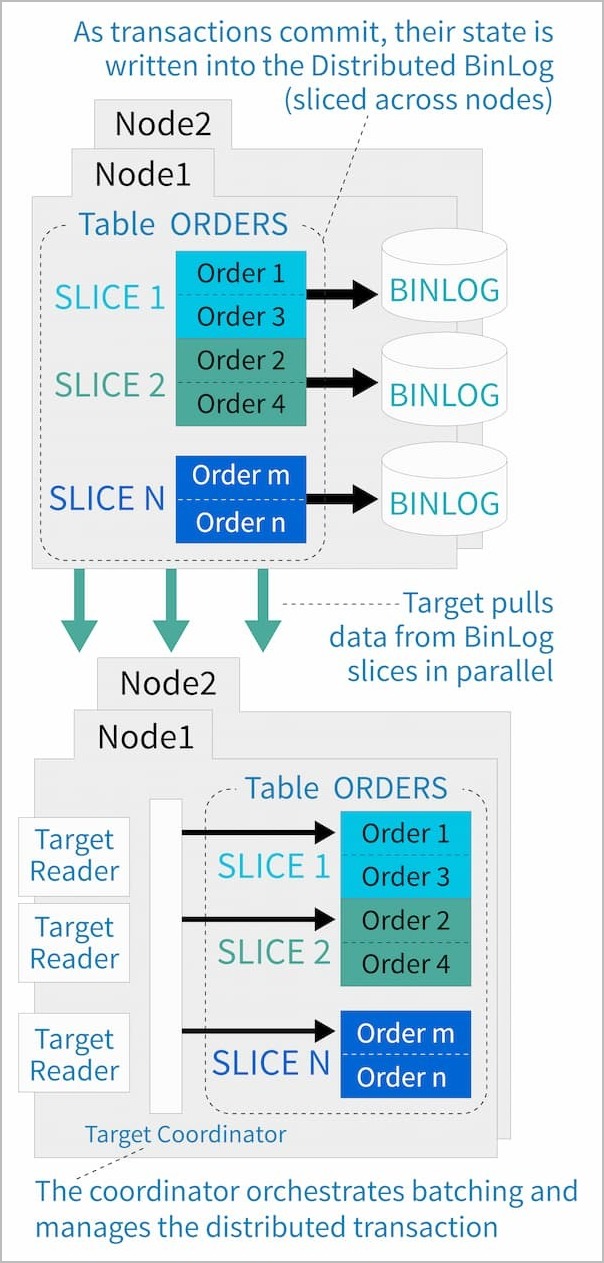
Parallel asynchronous replication with transactional consistency is the most appropriate option for disaster recovery on systems of high scale. As opposed to the other options, multiple nodes on the source cluster prepare and send messages, and multiple nodes on the destination cluster receive messages (see Figure 2). This system ensures that the throughput required will keep up with the heavy transaction load of the source system. The difference in transaction rate can be tenfold.
Figure 2: Parallel asynchronous replication

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}