GPT-2 (GPT2) vs. GPT-3 (GPT3): The OpenAI Showdown
The Generative Pre-Trained Transformer (GPT) is an innovation in the Natural Language Processing (NLP) space developed by OpenAI.
Join the DZone community and get the full member experience.
Join For FreeGPT-2 is an unsupervised deep learning transformer-based language model. The model is open source and is trained on over 1.5 billion parameters to generate the next sequence of text for a given sentence. GPT-3 is known to go further with tasks such as writing essays, text summarization, language translation, answering questions, and producing computer code. Version 3 takes the GPT model to a whole new level as it’s trained on a whopping 175 billion parameters.
Which Transformer Should I Go With: GTP-2 or GPT-3?
The Generative Pre-Trained Transformer (GPT) is an innovation in the Natural Language Processing (NLP) space developed by OpenAI. These models are known to be the most advanced of its kind and can even be dangerous in the wrong hands. It is an unsupervised generative model which means that it takes an input such as a sentence and tries to generate an appropriate response, and the data used for its training is not labelled.
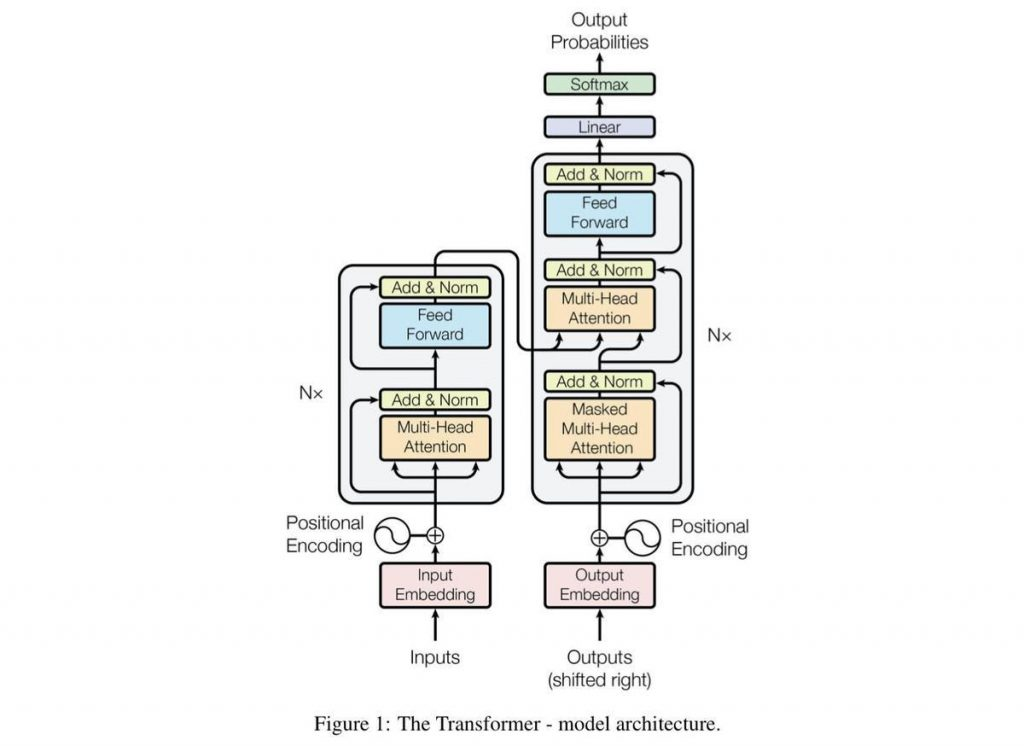
What Is GPT-2?

GPT-2 is an unsupervised deep learning transformer-based language model created by OpenAI back in February 2019 for the single purpose of predicting the next word(s) in a sentence. GPT-2 is an acronym for 'Generative Pretrained Transformer 2.' The model is open source, and is trained on over 1.5 billion parameters in order to generate the next sequence of text for a given sentence. Thanks to the diversity of the dataset used in the training process, we can obtain adequate text generation for text from a variety of domains. GPT-2 is 10x the parameters and 10x the data of its predecessor GPT.
Language tasks such as reading, summarizing and translation can be learned by GPT-2 from raw text without using domain specific training data.
Some Limitations In Natural Language Processing (NLP)
There are limitations that must be accounted for when dealing with natural language generation. This is an active area of research, but the field is too much into its infancy to be able to overcome its limitations just yet. Limitations include repetitive text, misunderstanding of highly technical and specialized topics and misunderstanding contextual phrases.
Language and linguistics are a complex and vast domain that typically requires a human being to undergo years of training and exposure to understand not only the meaning of words but also how to form sentences and give answers that are contextually meaningful and to use appropriate slang. This is also an opportunity to create customized and scalable models for different domains. An example provided by OpenAI is to train GPT-2 using the Amazon Reviews dataset to teach the model to write reviews conditioned on things like star rating and category.
What Is GPT-3?

Simply put, GPT-3 is the 'Generative Pre-Trained Transformer' that is the 3rd version release and the upgraded version of GPT-2. Version 3 takes the GPT model to a whole new level as it’s trained on a whopping 175 billion parameters (which is over 10x the size of its predecessor, GPT-2). GPT-3 was trained on an open source dataset called 'Common Crawl,' and other texts from OpenAI such as Wikipedia entries.
GPT-3 was created to be more robust than GPT-2 in that it is capable of handling more niche topics. GPT-2 was known to have poor performance when given tasks in specialized areas such as music and storytelling. GPT-3 can now go further with tasks such as answering questions, writing essays, text summarization, language translation, and generating computer code. The ability for it to be able to generate computer code is already a major feat unto itself. You can view some GPT-3 examples here.
For a long time, many programmers have been worried at the thought of being replaced with artificial intelligence and now that looks to be turning into reality. As deepfake videos gain traction, so too is speech and text driven by AI to mimic people. Soon it may be difficult to determine if you’re talking to a real person or an AI when speaking on the phone or commuincating on the Internet (for example, chat applications).
GPT-3 Could Be Called a Sequential Text Prediction Model
While it remains a language prediction model, a more precise description could be it is a sequential text prediction model. The algorithmic structure of GPT-3 has been known to be the most advanced of its kind thanks to the vast amount of data used to pre-train it. To generate sentences after taking an input, GPT-3 uses the field of semantics to understand the meaning of language and try to output a meaningful sentence for the user. The model does not learn what is correct or incorrect as it does not use labelled data; it is a form of unsupervised learning.
These models are gaining more notoriety and traction due to their ability to automate many language-based tasks such as when a customer is communicating with the company using a chatbot. GPT-3 is currently in a private beta testing phase which means that people must sign on to a waitlist if they wish to use the model. It is offered as an API accessible through the cloud. At the moment, the models seem to be only feasible in the hands of individuals/companies with the resources to run the GPT models.
An example of this model at play can be seen when we give the sentence, 'I want to go outside to play so I went to the ____.' In this instance, a good response can be something like a park or playground instead of something like a car wash. Therefore, the probability of park or playground on the condition of the prompted text is higher than the probability of car wash. When the model is being trained, it is fed millions of sample text options that it converts into numeric vector representations. This is a form of data compression which the model uses to turn the text back into a valid sentence. The process of compressing and decompressing develops the model’s accuracy in calculating the conditional probability of words. It’s opening a whole new world of possibilities, but it also comes with some limitations.
Some Limitations of GPT-2 and GPT-3
- While Generative Pre-Trained Transformers are a great milestone in the artificial intelligence race, it’s not equipped to handle complex and long language formations. If you imagine a sentence or paragraph that contains words from very specialized fields such as literature, finance or medicine, for example, the model would not be able to generate appropriate responses without sufficient training beforehand.
- It is not a feasible solution to the masses in its current state due to the significant compute resources and power that is necessary. Billions of parameters require an amazing amount of compute resources in order to run and train.
- It is another black-box model. In a business setting, it is mostly necessary for the users to understand the processes under the hood. GPT-3 is still not available to the masses, as it is exclusive to a select number of individuals now. Potential users must register their interest and await an invitation to be able to test the model themselves. This was done to prevent the misuse of such a powerful model. An algorithm that can replicate human speech patterns has many ethical implications on the whole of society.
GPT-3 Is Better Than GPT-2
GPT-3 is the clear winner over its predecessor thanks to its more robust performance and significantly more parameters containing text with a wider variety of topics. The model is so advanced even with its limitations that OpenAI decided it would keep it secure and only release it to select individuals that submitted their reasoning to use the model. Eventually they may look to release it as an API to be able to control requests and minimize misuse of the model.
Also important to note: Microsoft announced in September 2020 that it had licensed 'exclusive' use of GPT-3; others can still use the public API to receive output, but only Microsoft has control of the source code. Because of this, EleutherAI has been working on its own transformer-based language models loosely styled around the GPT architecture. One of their goals is to use their own GPT-Neo to replicate a GPT-3 sized model and open source it to the public, for free. You can view GPT-Neo progress on their GitHub repo here.
Artificial Intelligence has a long way to go before it deals a significant blow to the language generation space, since these models still cannot perfect the nuances of the human language. The level of accuracy needed and the type of tasks it needs to learn to tackle are still greater than its current capabilities. However, the rapid advancement in new GPT models is making it more likely that the next big breakthrough may be just around the corner.
Published at DZone with permission of Kevin Vu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments