How to Use Redis for Content Filtering
In this article, we look at how to implement Bloom Filters to search for keywords in James Joyce's epic work, 'Ulysses.'
Join the DZone community and get the full member experience.
Join For FreeRecently, a colleague of mine had a request: how can I create a content filter in Redis? He wanted to filter incoming messages against a list of bad words. It’s a pretty common use case — any app that accepts user input probably wants to do at least a cursory scan for inappropriate words. My first thought was that he should use a Bloom filter, but I wondered if there were better options, so I wanted to test my assumption. I fetched a list of bad words from here and did some initial testing with the text of Ulysses by James Joyce (a big book in the public domain with a lot of interesting language!).
For those who aren’t familiar, a Bloom filter is a probabilistic (p11c) data structure that can test for presence. This approach might seem intimidating at first, but it is really quite simple: you add items to a Bloom filter, then you check for existence in the Bloom filter. Bloom filters are probabilistic in that they can’t answer existence definitively — they either tell you an item is definitely not in the filter or probably in the filter. In other words, with Bloom filters false positives are possible but false negatives are not. The really cool thing about Bloom filters are that they use a fraction of the space (versus actually storing the items) and can determine probable existence with modest computational complexity. My wife, who is a literature professor, was very entertained that I picked Ulysses for this test, reminding me that the protagonist of the book is named Bloom. Fitting.
Back to the problem at hand. What you want to do is take all the words in a given message and find the intersection with a list of known bad words. Then you identify the words which are problematic and either reject or perhaps hand screen them.
To make things as easy to use as possible and avoid any network bottlenecks, I implemented all the solutions in Lua and ran them from within Redis. I used a Lua table with the keys as the inappropriate words and the values as “true” to prevent issuing unneeded Redis commands in all the scripts.
A note on message handling: in the scripts, I used a very simplistic method, just splitting by space. Admittedly, this alone would not work in practice because you would need to handle punctuation, numbers, etc. In this case, it worked fine since we were treating the scripts the same way and weren’t trying to measure the speed of Lua string splitting.
Using Sets for Content Filtering
Aside from a Bloom filter, another way to approach this problem is to use Redis Sets. The first thing I did was add the bad words to a SET key, using the SADD command and over 1600 arguments to that single command. I took the bad word list and surrounded each word with double quotes, then prefixed SADD and the key, and finally saved it all to a text file (badwords-set.txt). I executed it with this redis-cli piping trick:
$ cat ./badwords-set.txt | redis-cli -a YourRedisPasswordA simplistic approach would be to break up the message into words, and run SISMEMBER on each word in the message to identify the words. My initial thought was that the sheer number of commands would make this inefficient. Let’s look at how that’s implemented:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
local badwords = {}
for word,v in pairs(words) do
if redis.call('SISMEMBER', KEYS[1], word) == 1 then
table.insert(badwords,word)
end
end
return badwordsAll we’re doing here is splitting up the first argument (the message, in this case), then iterating over the words and running SISMEMBER for each one. If SISMEMBER returns a 1 then we know it’s a bad word and add it to a table which we return to Redis.
Earlier, I talked about an intersection between the bad words and the words of the message. Let’s do that quite literally with SADD and SINTER. Again, this seems like a ton of commands, but here’s how it looks in Lua:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
for word,v in pairs(words) do
redis.call('SADD',KEYS[1],word)
end
local badwords = redis.call('SINTER',KEYS[1],KEYS[2])
redis.call('UNLINK',KEYS[1])
return badwordsThis is the same split routine as before, but instead of issuing a SISMEMBER for every word, I added it to a temporary Redis set with SADD. Then I intersected this temporary set with our bad words using the SINTER command. Finally, I got rid of the temporary set with UNLINK and returned back the results of the SINTER. With this method, keep in mind that you’re writing to Redis. This has some implications to persistence and sharding, so the relative simplicity of the Lua script hides some operational complexity.
Content Filtering With Bloom
For my second approach, I added all the bad words to a Bloom filter. Like SADD, you can add multiple items at once to a Bloom filter with the BF.MADD command. In fact, I took the text file that contained all the bad words and the SADD command, and just replaced the command (now BF.MADD) and key.
With this solution, it’s important to keep in mind that Bloom filters are probabilistic — they can return false positives. Depending on your use case, this might require doing a secondary check on the results, or just using them as a screen for a manual process.
First, let’s take a look at a Lua script to check for bad words:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
local badwords = {}
for word,v in pairs(words) do
if redis.call('BF.EXISTS', KEYS[1], word) == 1 then
table.insert(badwords,word)
end
end
return badwordsSimilar to the SISMEMBER method, we can split up the incoming string into unique words and then run BF.EXISTS on each word. BF.EXISTS will return a 1 if it probably exists in the filter, or a 0 if it definitely does not. This solution compares each word in the message with the filter, inserts any bad words into a table, and returns it back in the end.
We can also use the ReBloom module, which offers the BF.MEXISTS command to check multiple strings versus the filter. It functions the same as BF.EXISTS, but allows you to do more at a time. However, things get a little tricky in this one. Running multiple commands, even from Lua, incurs some overhead for Redis, so, ideally, you want to run as few commands as possible, leaving Redis to actually check the data rather than spend resources interpreting thousands of commands. It’s best to minimize command calls by maximizing the number of arguments (that’s the theory at least).
My first attempt was to just take all the unique words of Ulysses (45,834) and shove them into one command of BF.MEXISTS using the unpack function. That didn’t work out, as Lua’s fixed stack size was far smaller than my 45k arguments. This forced me to split up my BF.MEXIST into smaller chunks of words. Trial and error helped me discover that I could safely add about 7,000 arguments to the BF.MEXISTS command before Lua complained. This came at the cost of Lua script complexity, but it meant that I could run 66 commands instead of over 45k.
Here is how the script ended up looking:
local words = {}
for i in string.gmatch(ARGV[1], "%S+") do
words[string.lower(i)] = true
end
local function bloomcheck(key,wordstocheck,dest)
for k, v in ipairs(redis.call('BF.MEXISTS',key,unpack(wordstocheck))) do
if v == 1 then
table.insert(dest,wordstocheck[k])
end
end
end
local possiblebad = {}
local temp = {}
local i = 0;
for word,v in pairs(words) do
table.insert(temp,word)
i = i+1;
if i == 7000 then
bloomcheck(KEYS[1],temp,possiblebad)
temp = {}
i = 0;
end
end
bloomcheck(KEYS[1],temp,possiblebad)
return possiblebadAs you can see, this is starting to be a substantial amount of Lua code. It goes through all the words to get chunks of 7,000, and then runs the bloomcheck function, which checks the filter for a chunk of values and adds those bad words to the temp table. Finally, it returns all the possible bad words.
Testing
Running Lua scripts from the CLI is not fun, since you’re dealing with large arguments and things can get sticky. So, I wrote a small Node.js script using the Benchmark.js framework to run my tests multiple times and get proper stats on each run. Aside from Ulysses, I also ran it on sets of 1,000 and 500 words of lorem ipsum random text to get a feel for shorter messages. All of these tests were run on my development laptop, so they have marginal meaning beyond relative differences.
Let’s look at the results:
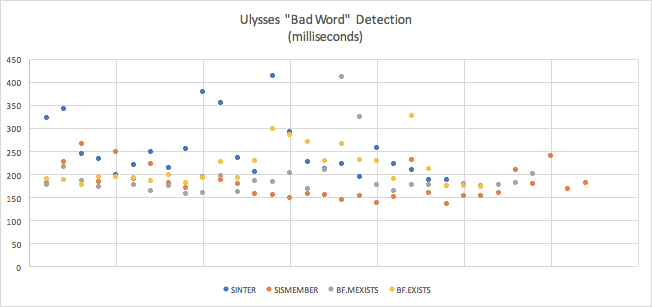
| Mean | Standard Deviation | Margin of Error | |
|---|---|---|---|
| SINTER (4th) | 0.252477065875 seconds (252.478ms) |
0.06331450637410971 | 0.026739796333907027 |
| SISMEMBER (1st) | 0.17936577490625 seconds (179.356ms) | 0.034054703041132506 | 0.011799352611322679 |
| BF.MEXISTS (2nd) | 0.19251170375862064 (192.512ms) | 0.05158925843435185 | 0.01961960405252156 |
| BF.EXISTS (3rd) | 0.21505565530769238 (215.056ms) | 0.041931428091619434 | 0.016940265013395354 |
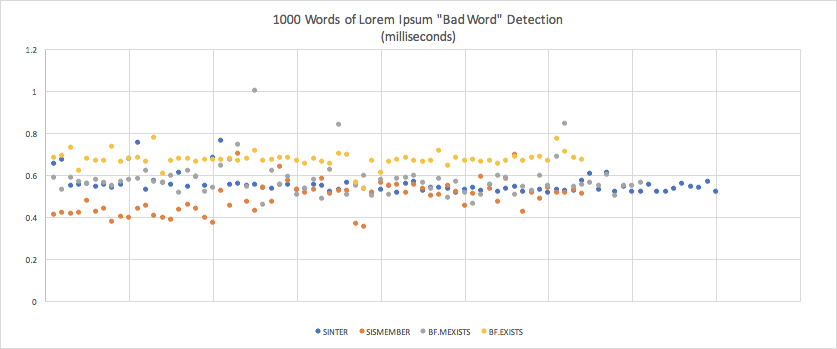
| Mean | Standard Deviation | Margin of Error | |
|---|---|---|---|
| SINTER (2nd) | 0.0005533430385665705 (0.55ms) | 0.00004782064272951418 | 0.00001047916037135063 |
| SISMEMBER (1st) | 0.0004876821613932592 (0.49ms) | 0.00007453275890098545 | 0.000018260525930741436 |
| BF.MEXISTS (3rd) | 0.0005750750453153705 (0.58ms) | 0.00008423403428371551 | 0.000019593611749182812 |
| BF.EXISTS (4th) | 0.0006705186154166669 (0.67ms) | 0.000035960357334688716 | 0.000008810287546998735 |
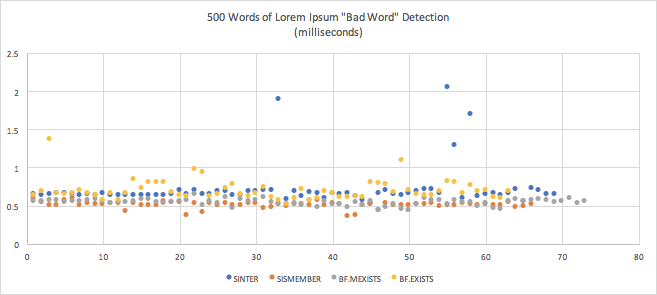
| Mean | Standard Deviation | Margin of Error | |
|---|---|---|---|
| SINTER (4th) | 0.0007199102990995225 (0.72ms) | 0.00026621924403751274 | 0.00006281610037055691 |
| SISMEMBER (1st) | 0.0005127359608872813 (0.51ms) | 0.000042812670318675034 | 0.000010328955827771373 |
| BF.MEXISTS (2nd) | 0.0005467939453535285 (0.55ms) | 0.00004135890147573503 | 0.00000948775881996386 |
| BF.EXISTS (3rd) | 0.0007052701613834288 (0.71ms) | 0.00013297426439345952 | 0.000032836237873305535 |
Conclusions
I thought these results were very interesting. My initial assumption was incorrect for this case — Bloom filters weren’t the fastest. Plain old SISMEMBER ran faster in all tests. A few of my important takeaways beyond this include:
- Ulysses is an unusual workload for this type of thing, you likely won’t have very many James Joyces submitting epic novels.
- All the 1000- and 500-word tests yielded sub-millisecond responses, putting them in the “instant” range. Response times varied by fractional milliseconds, so the differences wouldn’t be perceptible.
- If SISMEMBER had the ability to accept variadic arguments (it doesn’t), that would likely make it even faster in this situation.
- Some of the 500-word means were longer than the 1000-word means. My suspicion is that much of the time spent on these relatively small workloads is in overhead.
So why would you use Bloom filters then? Storage efficiency. Let’s look at one final thing:
127.0.0.1:6379> MEMORY USAGE badwordsset
(integer) 68409
127.0.0.1:6379> MEMORY USAGE badwords
(integer) 4228Here, “badwords” is the Bloom filter, while “badwordset” is the Set structure. The Bloom filter is more than 16X smaller than the set. In this case, size doesn’t matter that much since it’s a single list. But, imagine if every user on a site had his or her own badword filter? This would really add up using a Set structure, but using a Bloom filter it would be much easier to accommodate. And this test has shown that the response time is very similar.
Published at DZone with permission of Kyle Davis, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments