Microservices in Publish-Subscribe Communication Using Apache Kafka
Learn about publish-subscribe communication using Apache Kafka as messaging systems and validated through integration testing.
Join the DZone community and get the full member experience.
Join For FreePublish-Subscribe Messaging systems play an important role in any enterprise architecture as it enables reliable integration without tightly coupling the applications. The ability to share data between decoupled systems is not a problem that is easily tackled.
Consider an enterprise with multiple applications that are being built independently, with different languages and platforms. It needs to share data and processes responsively. We can achieve this using Messaging to transfer packets of data frequently, immediately, reliably, and asynchronously using customizable formats. Asynchronous messaging is fundamentally a pragmatic reaction to the problems of distributed systems. Sending a message does not require both systems to be up and ready at the same time.
Publish-Subscribe Channel
From a simple perspective, the understanding of this pattern relies on its expands upon the Observer pattern by adding the notion of an event channel for communicating event notifications. The Observer pattern describes the need to decouple observers from their subject so that the subject can easily provide event notification to all interested observers no matter how many observers there are.
Each subscriber needs to be notified of a particular event once but should not be notified repeatedly of the same event. The event cannot be considered consumed until all of the subscribers have been notified. Once all of the subscribers have been notified, the event can be considered consumed and should disappear from the channel [2].
Broker, Queues, Topics, and Subscriptions
Brokered messaging supports the scenario of truly temporal decoupled systems where either message producer or consumer availability is not guaranteed. With Brokered messaging, the queue is the broker that retains a message created by a producer and where the consumer can retrieve the message when ready.
Queue provides the simplest message delivery option. Messages in a Queue are organized by first-in, first-out (FIFO), and each message is expected to be processed by a single consumer; however, Topics and Subscriptions constitute a publish/subscribe pattern allowing the same message to be processed by N number of consumers.
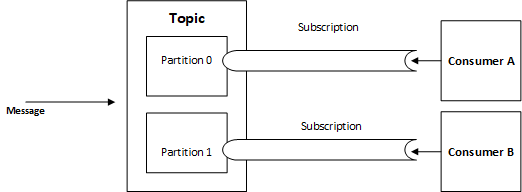
Publish-Subscribe Messaging System
A single message can be added to a topic, and for every subscription rule that is satisfied, a copy of the message will be added to that subscription. In this case, each subscription becomes the queue, where consumers can process the messages on a subscription individually.
One of the reliable and mature projects that are being utilized by industry leaders is Apache Kafka which provides us the capability to handle a huge number of messages per second, instead of traditional messaging systems that have been quite useful in traditional scenarios but not efficient and valuable in handling Big Data scenarios.
Beyond messaging, Apache Kafka can be applied in stream processing, website activity tracking, log aggregation, metrics, time-based message storage, commit log, and event sourcing.
Kafka and Zookeeper
Kafka is a distributed publish-subscribe messaging system that is fast, scalable, and distributed in nature by its design, partitioned, and replicated commit log service. It differs from a traditional messaging system in being very easy to scale out, offers high throughput, to supports multi-subscribers, automatically balances the consumers during failure, and has the ability to allow real-time applications or ETL to use it as batch consumption of persisted messages on disk [1].
ZooKeeper is used to manage and coordinate the Kafka broker. Each Kafka broker is coordinated with other Kafka brokers using ZooKeeper. The producer and consumer are notified by the ZooKeeper service about the presence of a new broker or failure of the broker in the Kafka system. From the notification received by the Zookeeper regarding the presence or failure of the broker, the producer and consumer take the decision and start coordinating their work with some other broker. Also, it is responsible for choosing the new leaders for the partitions.
Case Study
After a little state of art lets, focus on practice. So, our case study simulates the communication between two microservices built with Spring Boot micro-framework v2.1.8.RELEASE in publish-subscribe context, using Apache Kafka 2.3.1 as a message system. To validate our study, we will be setting and executing an integration test that focuses on integrating different layers of the application in an end to end scenarios with the JUnit 4/5 testing framework.
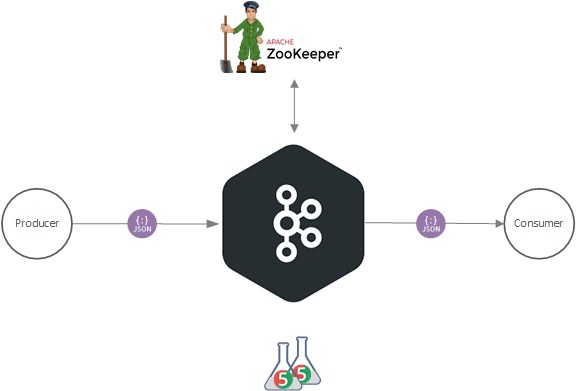
Publish-Subscribe Messaging System
The Producer API is a module that implements the operation of a business entity service to coordinate and harmonize economic information relating to enterprises, establishments, and groups of entities. The Consumer API is another module in the same solution which aims to centralize all business entity statistics, receiving data input from a different source.
For the sake of simplicity, the APIs use the H2 in-memory database. The project structure is composed of three modules. Both major modules, Producer and Consumer, have a dependency on the Common module, which shares things like error handling and auxiliary classes with the remaining part of the system.
The sample is accessible from the GitHub repository; to download it, please follow this link.
Let's get started.
Integrating Spring Kafka With Apache Kafka Message System
The Spring for Apache Kafka project applies core Spring concepts to the development of Kafka-based messaging solutions. It provides a "template" as a high-level abstraction for sending messages. It also provides support for Message-driven POJOs with @KafkaListener annotations and a "listener container." These libraries promote the use of dependency injection and declarative [3].
Producer API
We need two steps to config a producer. The first one is the config class, where we define the producer Map object, the producer factory, and the Kafka template. The second is respected to the service class when we set the message builder to publish in Kafka broker.
Producer Config
In the configuration class, the constant bootstrapServers , which is the Kafka server set in application.properties. Using the @Value("${spring.kafka.bootstrap-servers}") annotation indicates a default value expression for the affected argument.
To create a Kafka producer, we define certain properties that we pass to the constructor of a Kafka producer. In producerconfigs @Bean we set the BOOTSTRAP_SERVERS_CONFIG property to the list of broker addresses we defined earlier in application.properties. BOOTSTRAP_SERVERS_CONFIG value is a comma-separated list of host/port pairs that the Producer uses to establish an initial connection to the Kafka cluster.
package com.BusinessEntityManagementSystem;
import ...
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, BusinessEntity> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, BusinessEntity> kafkaTemplate() {
return new KafkaTemplate<String, BusinessEntity>(producerFactory());
}
}The KEY_SERIALIZER_CLASS_CONFIG is a Kafka Serializer class for Kafka record keys that implements the Kafka Serializer interface. Notice that we set this to StringSerializer.class as the message ids. The VALUE_SERIALIZER_CLASS_CONFIG is a Kafka Serializer class that we set to JsonSerializer.class as the message body.
To create messages, first, we need to configure a ProducerFactory, which sets the strategy for creating Kafka Producer instances. Then we need a KafkaTemplate which wraps a Producer instance and provides convenience methods for sending messages to Kafka topics using our data transfer object BusinessEntity.
Producer Service
In the Kafka Producer Service class, the @Service annotation indicates that the annotated class is a Service. In this class, we implement the method to send the messages to the Kafka broker, declaring the topic attribute on the header predefined in the application.properties.
package com.BusinessEntityManagementSystem.kafka;
import ...
@Service
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, BusinessEntity> kafkaTemplate;
@Value("${statistics.kafka.topic}")
String kafkaTopic;
public void send(BusinessEntity payload) {
Message<BusinessEntity> message = MessageBuilder
.withPayload(payload)
.setHeader(KafkaHeaders.TOPIC, kafkaTopic)
.build();
kafkaTemplate.send(message);
}
}Consumer API
In consumer, we need to add the appropriate Deserializer, which can convert JSON byte[] into a Java Object. To set it, we need the class config and the class annotated with @components that will autodetect this class for dependency injection when annotation-based configuration and classpath scanning is used.
Consumer Config
As well, as we specify the KEY_SERIALIZER_CLASS_CONFIG, VALUE_SERIALIZER_CLASS_CONFIG to serialize the message published by the producer, we also need to inform the Spring Kafka about constant values for deserialization like KEY_DESERIALIZER_CLASS_CONFIG and VALUE_DESERIALIZER_CLASS_CONFIG. Beyond the constants referenced above, we specify the GROUP_ID_CONFIG and AUTO_OFFSET_RESET_CONFIG as the earliest, allowing the consumer to read the last inserted message in the broker.
To enable Kafka listeners, we use the @EnableKafka annotation. These annotated endpoints are created under the covers by an AbstractListenerContainerFactory. The KafkaListenerContainerFactory is responsible for creating the listener container for a particular endpoint. It enables the detection of KafkaListener annotations on any Spring-managed bean in the container.
As typical implementations, the ConcurrentKafkaListenerContainerFactory provides the necessary configuration options that are supported by the underlying MessageListenerContainer.
package com.BusinessStatisticsUnitFiles;
import ...
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "statistics-BusinessStatisticsUnitFiles-group");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
@Bean
public ConsumerFactory<String, BusinessEntity> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(
consumerConfigs(),
new StringDeserializer(),
new JsonDeserializer<>(BusinessEntity.class, false));
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, BusinessEntity> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, BusinessEntity> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}On the consumer factory, we can disable the use of headers. This is achieved now by set to false the second parameter in newJsonDeserializer<>(BusinessEntity.class, false));. This allows the consumer to trust messages that come from any package.
Consumer "Service"
For consuming messages, It is necessary to have configured the ConsumerFactory and a KafkaListenerContainerFactory as we did above. Once these beans are available in the Spring Bean factory, POJO-based consumers can be configured using @KafkaListener annotation.
@KafkaHandler also is necessary to mark a method to be the target of a Kafka message listener within a class that is annotated with @KafkaListener. It is important to understand that when a message arrives, the method selected depends on the payload type.
The type is matched with a single non-annotated parameter or one that is annotated with @Payload. There must be no ambiguity — the system must be able to select exactly one method based on the payload type.
package com.BusinessStatisticsUnitFiles.kafka;
import ...
@Component
public class KafkaConsumer {
@Autowired
IBusinessEntityRepository businessEntityRepository;
private static final Logger LOG = LoggerFactory.getLogger
(BusinessEntity.class);
@KafkaListener(topics = "${statistics.kafka.topic.create.entity}",
groupId = "statistics-BusinessEntityManagementSystem-group")
@KafkaHandler
public void receiveCreatedEntity(@Payload BusinessEntity data,
@Headers MessageHeaders headers) {
businessEntityRepository.save
(RetrieveConsumerFromReceivedProducerObject.Binding
(new BusinessEntityModel(), data));
}
}The @Payload annotation binds a method parameter to the payload of a message. It can also be used to associate a payload to a method invocation. The payload may be passed through a MessageConverter to convert it from serialized form with a specific MIME type to an Object matching the target method parameter. Our class annotated with @Payloadis the BusinessEntity DTO.
Spring Boot also supports retrieval of one or more message headers using the @Headers annotation in the listener. Multiple listeners can be implemented for a topic, each with a different group Id. Furthermore, one consumer can listen to messages on various topics.
As you may have noticed, we created the topic building with only one partition. However, for a topic with multiple partitions, a @KafkaListener can explicitly subscribe to a particular partition of a topic with an initial offset.
Application.Properties
Last but not least, in our configuration, we specify some values related to the behavior of communication between Producer and Consumer.
Producer/Consumer
On each Producer and Consumer API, we define the Kafka cluster we want our microservices to connect with, using the spring.kafka.bootstrap-servers=localhost:9092. Also, it is necessary to define the topic name to produce and receive messages, the key, as well as the group-id.
...
## Application.properties Kafka config
spring.kafka.bootstrap-servers=localhost:9092
statistics.kafka.topic=test
statistics.kafka.key=test
statistics.kafka.topic.create.entity=test
spring.kafka.producer.group-id=statistics-BusinessStatisticsUnitFiles-group
spring.kafka.template.default-topic=test
...Preparing the Kafka and Zookeeper for Integration Test
The steps defined below demonstrate how to run and test Kafka on Windows 10 operating system.
Download Kafka With Embedded Zookeeper
- Download the Kafka binaries. This post is based on
Kafka 2.3.1, and hence we assume that you are downloading a2.3.1 versionforScala 2.12. - Un-zip the
kafka_2.12-2.3.1.tgzfile.
Setting Zookeeper.Properties
To make it work, we need to change the Zookeeper data directory location.
Open the kafka\config\zookeeper.properties file and change the Zookeeper data /log directory location config to a valid Windows directory location.
dataDir=C:\\kafka\\zookeeper-logsSetting Server.Properties
We also need to make some changes to the Kafka configurations. Open kafka\config\server.properties and set topic defaults to one. We will be running a single-node Kafka. Also, to prevent Kafka from creating unnecessary numbers of offset, we specify the replicas to 1.
We faced this issue on the Windows environment with the latest Kafka 2.3.1 version. This led Kafka to stop because of insufficient memory to handle a bunch of data created automatically on the initial phase of starting the server.
############################# Log Basics #############################
log.dirs=C:\\kafka\\kafka-logs
####################### Internal Topic Settings #####################
offsets.topic.replication.factor=1
offsets.topic.num.partitions = 1
min.insync.replicas=1
default.replication.factor = 1
...To finish the Kafka configuration, add Kafka bin\windows directory to the PATH environment variable.
Create and Executing Integration Test
As the name suggests, integration tests focus on integrating different layers of the application, where no mocking is involved. The integration tests need to start up a container to execute the test cases. Hence, some additional setup is required for this, but with Spring Boot, these steps are easy using some annotations and libraries.
Test Class
The first annotation @RunWith(SpringRunner.class) is used to provide a bridge between Spring Boot test features and JUnit. SpringRunner.class enables full support of spring context loading and dependency injection of the beans in the tests. @SpringBootTest creates ApplicationContext tests through SpringApplication that will be utilized in our tests. It bootstraps the entire container from the embedded server and creates a web environment.
In our test, we are mimicking the real web environment setting it as RANDOM_PORT that also loads WebServerApplicationContext. The embedded server is started and listened to on a random port.
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {BusinessEntityManagementApplication.class}, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
class BusinessEntityIntegrationTest {
@LocalServerPort
private int port;
@Autowired
TestRestTemplate restTemplate;
HttpHeaders headers = new HttpHeaders();
...@LocalServerPort annotation provides us with the injected HTTP port that got allocated at runtime. It is a convenient alternative for @Value("${local.server.port}").
To access a third-party REST service inside a Spring application, we use the Spring RestTemplate or TestRestTemplate the convenient alternative that is suitable for integration tests by injecting it in our test class. With spring-boot-starter-test dependency in our project, we can access to TestRestTemplate class in runtime.
Test Method
In our test method, we are using the junit-json-params , a Junit 5 library that provides annotations to load data from JSON Strings or files in parameterized tests. We also annotated the method with @ParameterizedTest annotation to complement the library below. It is used to signal the annotated method is a parameterized test method. That method must not be private or static. They also must specify at least one ArgumentsProvider via @ArgumentsSource or a corresponding composed annotation.
Our @ArgumentsSource is a JSON file @JsonFileSource(resources = "/business-entity-test-param.json") inside the test. resources package. @JsonFileSource lets you use JSON files from the classpath. It supports single objects, arrays of objects, and JSON primitives.
The JSON object retrieved from the file is bound to the method params object that it is converted to a POJO object, in this case, our entity model.
@ParameterizedTest
@JsonFileSource(resources = "/business-entity-test-param.json")
@DisplayName("create business entity with json parameter")
void createBusinessEntity(JsonObject object) throws IOException,
URISyntaxException {
BusinessEntityModel businessEntityModel;
businessEntityModel = new BusinessEntityModel();
ObjectMapper mapper = new ObjectMapper();
businessEntityModel = mapper.readValue(object.toString(),
BusinessEntityModel.class);
HttpEntity<BusinessEntityModel> request = new
HttpEntity<>(businessEntityModel, headers);
try {
ResponseEntity<String> response =
this.restTemplate.postForEntity(createURLWithPort
("/api/businessEntityManagementSystem/v1/businessEntity"),
request, String.class);
assertAll(
() -> assertThat(response.getStatusCodeValue())
.isEqualTo(HttpStatus.CREATED.value()),
() -> assertThat(response.getHeaders().getLocation()
.getPath()).contains("/v1")
);
}
catch(HttpClientErrorException ex) {
assertAll(
() -> Assert.assertEquals(HttpStatus.BAD_REQUEST.value(),
ex.getRawStatusCode()),
() -> Assert.assertEquals(true, ex.getResponseBodyAsString()
.contains("Missing request header"))
);
}
}After the arrangement and acts, we assert if our call to the rest API returns the desired result.
Run Integration Test

Intellij Integration test
In our development environment, we need to grant that our Kafka and Zookeeper are up and running in two different consoles, as described in the figure.
Kafka needs Zookeeper, so we will first start Zookeeper using the below command.
c:\kafka>.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesIt should start the zookeeper server. Minimize the command window and let the zookeeper run in that window. Start a new command window and start Kafka Broker using the below command.
c:\kafka>.\bin\windows\kafka-server-start.bat .\config\server.propertiesNext, we will run our Consumer API in our IDE, or we can also deploy it.
Finally, we can execute the test class as a JUnit test. It will start the server and deploy the API, as it will be done normally. Then It will execute the tests. You can verify the tests in the JUnit tab of your IDE.
Conclusion
In this article, we have seen how we can use the publish-subscribe pattern to share data frequently, immediately, reliably, and asynchronously using customizable formats between two distinct microservices and validate it with an integration test through different layers in an end-to-end scenario.
References
[1] Kafka 2.3 Documentation;
[2] Gregor Hohpe, Bobby Woolf, Enterprise Integration Patterns Designing, Building, and Deploying Messaging Solutions, 2003;
[3] Spring for Apache Kafka 2.3.3.
Further Reading
How Are You Microservices Talking?
Opinions expressed by DZone contributors are their own.
Comments