Why is database migration such a critical topic of conversation? It is essential to first understand how the issue ties directly to the success of today's modern business. Since the introduction of SQL, the importance of data has grown exponentially, and in tandem, so has the need to learn and apply the concepts of SQL databases. Academia and industry both found new and compelling uses for data. This naturally led colleges to teach relational principles. As graduates entered the workforce, relational databases were used in systems development, which resulted in many businesses running legacy software systems that are now struggling to scale and meet the needs of the modern Internet customer.
Relying on legacy systems can result in lagging behind the smaller start-ups using modern solutions and cloud-based services, including NoSQL. These start-ups can scale their offerings far beyond what the legacy systems can offer. The loss of market share for these companies has opened a new market for industry solutions that help businesses with legacy systems migrate their data infrastructure to NoSQL and educate engineering teams about efficient implementation of it with the hopes of maintaining and regaining lost market share.
Making this leap isn’t as hard as it might seem. Next, we'll cover the basics (and a comparison) of SQL and NoSQL data modeling.
NoSQL Data Modeling
The fundamental principles around NoSQL data modeling are the same as those used for SQL. The difference comes down to denormalization vs. normalization of data and the minor shift in the shared approaches that this causes. Below is a Venn diagram showing a high-level view of data modeling for SQL and NoSQL.
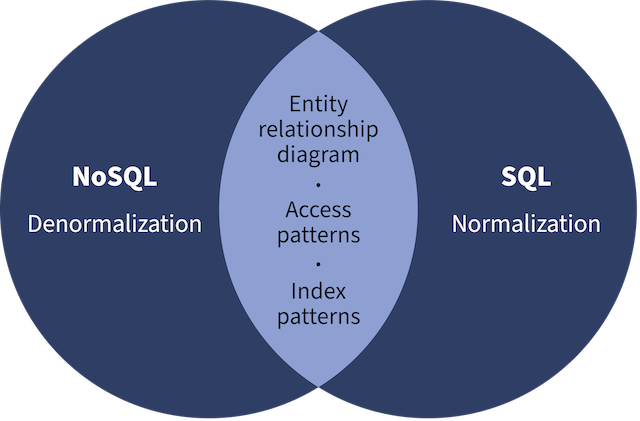
The process of creating an entity relationship diagram, understanding your application’s access patterns, and then optimizing data throughput by using indexes is the same for both SQL and NoSQL. So let’s now focus on understanding the differences between normalization and denormalization.
The process of creating an entity relationship diagram, understanding your application’s access patterns, and then optimizing data throughput by using indexes is the same for both SQL and NoSQL. So let’s focus on understanding the differences between normalization and denormalization.
Denormalizing Data
What Is Normalization? …Just Be Like Everyone Else
The objectives of normalization are to reduce data redundancy and the amount of data storage used, as well as to improve data integrity. In his paper, "Further Normalization of the Data Base Relational Model," Edgar Codd defined four forms of data normalization:
Form |
Purpose |
1NF (First Normal Form) |
Remove unnecessary insertions, updates, and deletion dependencies from the data model — all values must be atomic |
2NF |
Optimize your data model so when new data types are required, restructuring the schema is unneeded — non-key values must have a clear connection to the primary key |
3NF |
Remove transitive dependencies within the data model |
4NF |
Identify statistics that could change in the future; make changes to the data model relationships so querying for these statistics is neutral |
Following this process results in a set of tables with well-defined constraints that meet the objectives of reduced data redundancy and keeping data integrity intact.
What Is Denormalization? — Only Exceptional Data Need Apply!
The objective of denormalization is to design all access patterns in the most efficient way possible. Data access patterns are a main focus, and careful analysis is needed to attain that efficiency. This is done by combining or nesting data into one structure, which makes the reads and writes faster and avoids the overhead of joins.
Some people think that NoSQL is schema-less; however, this isn't true. All applications have an inherent logical data structure, which still exists in a NoSQL database — it is just stored implicitly. By utilizing this capability, joins can be reduced, allowing the application to retrieve all necessary information using a single lookup.
Before jumping into the example, let's first review the possible variations of NoSQL data models.
NoSQL Models
For SQL data solutions, a table is the core data model. However, there are multiple models for NoSQL data solutions to choose from. This mainly depends on the NoSQL database you are using — the four most popular types:
- Key-value pair
- Column-oriented
- Graph-based
- Document-oriented
Many NoSQL databases support two or more of these models. These are known as "multi-model" databases.
Quick note: In a later section, a simple music site is used to demonstrate denormalization. The data used in the models below — band and song names — are taken from that example.
Key-Value Pair
For key-value pair NoSQL databases, the model consists of a key and value:
Primary Key |
Value |
Band Name |
Coldplay |
But for more complex data structures, the value can be a JSON object, which is greater in depth and complexity. Typically, text is used as the visualization model for JSON structures.
Primary Key: Band Name
Value:
{
"Band Name": "Coldplay",
"Year": 2002,
"Origin": "Sheffield, England"
}
Column-Oriented
For column-oriented NoSQL databases, tables (or "column families", since they are fundamentally different from relational tables) can be used to show the column data structures. Tables can have multiple header rows — one for each data structure:
Primary Key |
Attributes |
Band Name |
Year |
Origin |
Band Members |
Arctic Monkeys |
2002 |
Sheffield, England |
Alex Turner, Jamie Cook, Nick O'Malley, Matt Helders |
Song Name |
Year |
Peak Chart Pos |
|
When the Sun Goes Down |
2018 |
1 |
|
This model shows two data structures, Band Name and Song Name.
Graph-Based
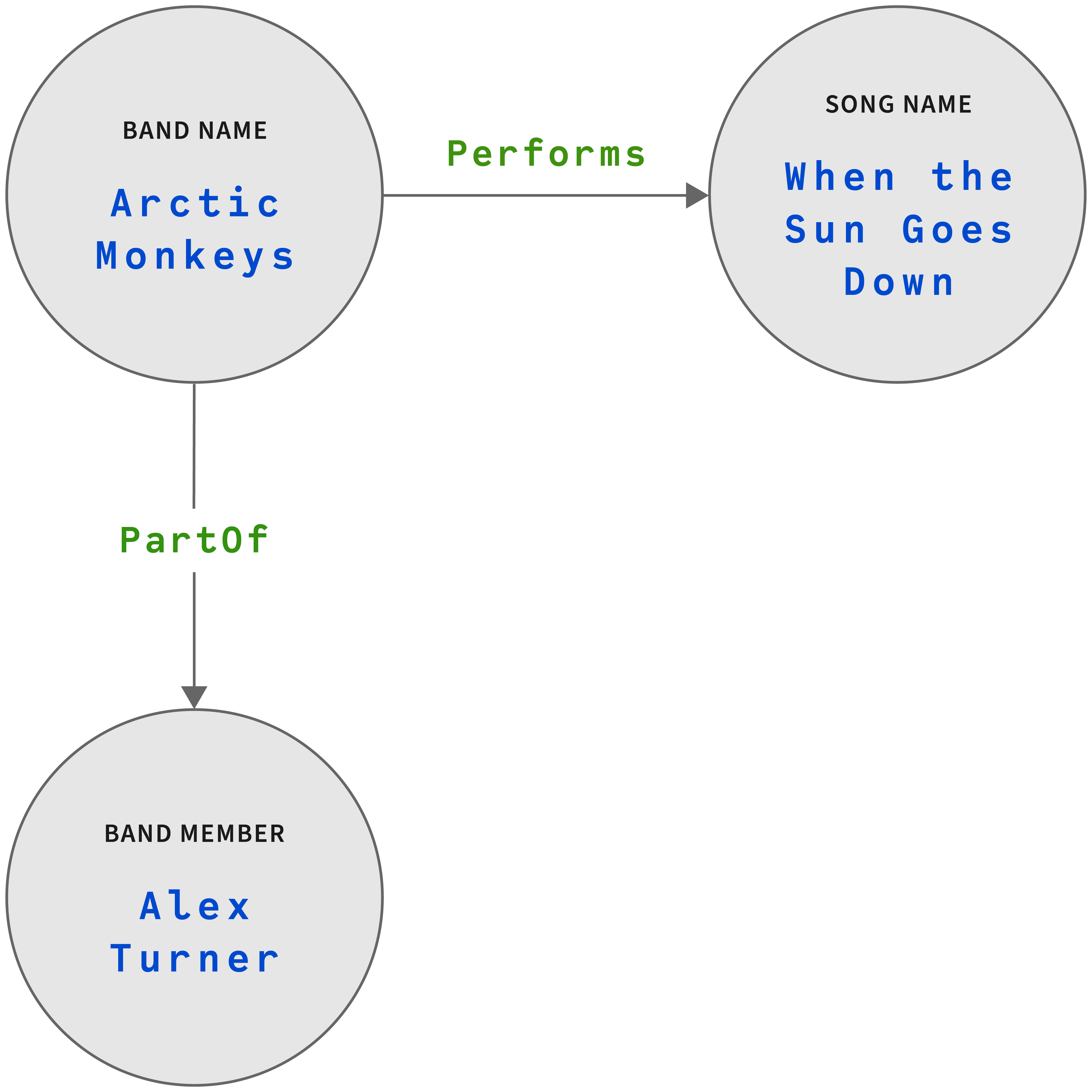
For graph-based NoSQL databases, the model consists of nodes and edges. Data structures are put into nodes, and relationships are represented by the edges that join one node to another. For example, visualizing a band, the songs that the band performs, and the members of the band might be modeled this way:
Document-Oriented
Document-oriented NoSQL databases have a primary key and a JSON value.
Primary Key: Arctic Monkeys
Value:
{
"Band Name": "Arctic Monkeys",
"Year": 2002,
"Origin": "Sheffield, England",
"Band Members": [
"Alex Turner",
"Jamie Cook",
"Nick O'Malley",
"Matt Helders"
],
"Genres": [
"Indie rock",
"garage rock",
"post-punk revival",
"psychedelic rock",
"alternative rock"
]
}
Because all SQL models use tables, describing the migration process from SQL to NoSQL with tables may be a more applicable depiction that resonates with those coming from an SQL background. Therefore, in the following sections, a table model will be used.
With the base knowledge about NoSQL databases, let's dive into how denormalization works.
Moving Data Into a NoSQL Database
To demonstrate the core concept of denormalization, we'll walk through the design of a data solution from the beginning. However, most likely you will have gone through the initial phase(s) in building your current SQL data solution.
When creating any data solution, whether SQL or NoSQL, you should consider following these steps:
- Understand your application – Use design tools and processes that are best suited to illustrate your problem domain and its design. For this example, I use wire diagrams.
- Build an entity relationship diagram – Capture the data structures and the relationships between them.
- Define your access patterns – The data that should be grouped together for optimal data delivery based on the application's needs.
- Design your primary keys and indexes – Analyze the best way to design the primary keys and indexes for optimal data delivery.
For this example, our problem domain is a simple music site where users are presented with a list of songs and associated data, as well as links to more information about each song and band.
1: Understand Your Application
The functionality this application will provide is allowing users to choose a song or band they want to read more details about. Below is the Home screen of our simple music site.
Functionality: Present a list of songs with links to song and band details.

Users can select the song name to navigate to song details or the band name to navigate to band details.
The data model for the Home screen:
Primary Key |
Attributes |
Home Screen |
Song Name |
Band Name |
Year |
Peak Chart Pos |
Yes |
When the Sun Goes Down |
Arctic Monkeys |
2018 |
1 |
Yes |
Yellow |
Coldplay |
2000 |
2 |
Note that accessing this data structure will be done using the Home Screen column, and therefore, indexing this column may be necessary for improved performance.
Functionality: Allow users to view song details.

The model for the Song Details screen:
Primary Key |
Attributes |
Band Name - Song Name |
Album |
Year |
Peak Chart Pos |
Lyrics |
Arctic Monkeys - When the Sun Goes Down |
Whatever People Say I Am, That's What I'm Not |
2018 |
1 |
So who's that girl there? I wonder what went wrong So that she had to roam the streets |
Coldplay - Yellow |
Parachutes |
2000 |
2 |
Look at the stars Look how they shine for you And everything you do |
Note that if your primary key must be a number, then hashing the string value into a number will work as well.
Functionality: Allow users to view band details.

The model for the Band Details screen:
Primary Key |
Attributes |
Band Name - Details |
Year |
Origin |
Band Members |
Genres |
Arctic Monkeys - Details |
2002 |
Sheffield, England |
Alex Turner, Jamie Cook, Nick O'Malley, Matt Helders |
Indie rock, garage rock, post-punk revival, psychedelic rock, alternative rock |
Coldplay - Details |
1996 |
London, England |
Chris Martin, Jonny Buckland, Guy Berryman, Will Champion, Phil Harvey |
Alternative rock, pop rock, post-Britpop, pop |
Note that the Band Members and Genres columns are both arrays, representing a one-to-many embedded relationship.
2: Build an Entity Relationship Diagram
The entity relationship diagram looks like this:

There are four entities: Band Name, Song Name, Genre, and Band Member. And there are three relationships, Perform, BelongsTo, and PartOf — all of which are one-to-many.
3: Define the Access Patterns
Access patterns are the data patterns/groupings needed for the application. In our music site, we have Song Name and Band Name, and the access patterns for each of the wire diagrams are:
- Home screen – Displays the list of songs
- Song Details screen – Displays song details
- Band Details screen – Displays band details
To better understand these access patterns, let’s look at a composite data model for all wire diagrams (data sourced from Tables 4-6):
Primary Key |
Attributes |
Home Screen |
Song Name |
Band Name |
Year |
Peak Chart Pos |
Yes |
When the Sun Goes Down |
Arctic Monkeys |
2018 |
1 |
Yes |
Yellow |
Coldplay |
2000 |
2 |
Band Name - Song Name |
Album |
Peak Chart Pos |
Year |
Lyrics |
Arctic Monkeys - When the Sun Goes Down |
Whatever People Say I Am, That's What I'm Not |
1 |
2018 |
So who's that girl there? I wonder what went wrong So that she had to roam the streets |
Coldplay - Yellow |
Parachutes |
2 |
2000 |
Look at the stars Look how they shine for you And everything you do |
Band Name - Details |
Band Members |
Origin |
Year |
Genres |
Arctic Monkeys - Details |
Alex Turner, Jamie Cook, Nick O'Malley, Matt Helders |
Sheffield, England |
2002 |
Indie rock, garage rock, post-punk revival, psychedelic rock, alternative rock |
Coldplay - Details |
Chris Martin, Jonny Buckland, Guy Berryman, Will Champion, Phil Harvey |
London, England |
1996 |
Alternative rock, pop rock, post-Britpop, pop |
The beneficial part about denormalizing data this way is that when queried using a primary key, the application retrieves the data needed to satisfy the functionality without resorting to joins. The downside of denormalizing your data is that some data may be duplicated (i.e., Band Name, Year, Peak Chart Pos). In a fully normalized SQL database, data isn't duplicated, and data integrity is maintained by the database through table constraints.
To meet scalability needs, a NoSQL database has duplicated data and moves the responsibility of data integrity to the application code. When data needs to be updated in multiple places, it is the application’s responsibility to keep all data structures up to date.
While not possible in every NoSQL database, many document databases have recently introduced JOIN capability. With JOIN functionality, you can design your model to take advantage of whichever approach is best. You can denormalize to maximize performance, and you can normalize to maximize data integrity.
4: Design Your Primary Keys and Indexes
In the composite table above, there are separate primary keys for each data structure used. By querying this single table, you can extract different schemas or groups of data. The Home screen’s primary key is the Home Screen column. When the Home Screen column is queried, it will look for data that has a Home Screen attribute set to yes. Therefore, an index should be created on the Home Screen attribute, so that look up will be as fast as possible. The Song Details primary key uses a string that consists of the Band Name and Song Name concatenated together. The Band Details primary key uses a string consisting of the Band Name followed by - Details. These primary keys are designed this way to give the application the data it needs in the quickest manner possible.
Common Migration Paths
In most cases, legacy solutions are unable to meet organizations’ scalability objectives. And the engineering teams supporting those legacy applications may not be aware of NoSQL database principles; however, they have a tremendous amount of application and domain knowledge. In short, companies in these situations have two primary routes for migrating to a NoSQL database.
Direct Port
Every business' situation is unique, and the migration approach will inevitably be unique as well. A direct port will be easiest if your current data solution has a clear decoupling between the application logic and data. If the application data layer is designed in a manner that allows pulling out one database architecture and replacing it with another, then it's just a matter of implementing the data layer interface using NoSQL. However, if your engineering team needs to create a clear decoupling of the application logic and data, that work will need to be completed first. Then they can implement the data layer interface using NoSQL.
These tasks may be done in parallel with one team coming up to speed on NoSQL— and following the four steps for creating a new data solution discussed above — while the other team does the architectural work of decoupling the application logic and data. Then when both teams are ready, the application can be switched from an SQL database to a NoSQL database.
Piecemeal
In cases when a legacy application must remain running to keep the business operational, switching the entire data layer over at once isn't reasonable. Depending on the size of the data layer and the number of engineering teams involved, migrating piecemeal may be an option. Oftentimes, the areas where the application struggles under the current SQL data layer is known. Focus your engineering efforts there first, porting the critical code over in a piecemeal fashion.
SQL and NoSQL Working Together
If your application’s data layer involves using multiple databases, you can choose to port over one database to a NoSQL solution while leaving the other alone. This approach works well in a cloud-native environment where multiple microservices are running. Teams should start with the service that is under the most stress and then move to the next service. When a monolith is involved, a careful process needs to be followed where you would wall off the part that has the most pressing issues with scaling. After decoupling this part, it starts to look like a microservice, and you can then focus on the data layer porting process. Once complete, the next piece of the monolith can be addressed, repeating the process.
Convert to NoSQL While Still Using SQL Queries
The market has recognized the need for businesses to migrate to a NoSQL solution. And those currently using an SQL solution also need a bridge that enables them to move incrementally into a full NoSQL database. This method offers three things:
- Businesses can address their scalability objectives.
- Engineering teams have time to come up to speed on NoSQL principles.
- Businesses have more options for addressing and evolving their data solution going forward.
There are solutions available that allow you to convert your SQL schema over to a NoSQL database while continuing to use SQL queries. There are also NoSQL databases that are implementing the "SQL++" standard: adding denormalized capabilities to the familiar query language. This approach may help teams ramp up to NoSQL faster, building on their existing experience and code base. (With the advent of SQL++, the term "NoSQL" can be defined as "Not Only SQL": SQL is still an option for interacting with data, but it's not the only one).
After, the business can operate as normal and only address the areas where scalability has become a critical issue, leaving the rest of their data solution as is. As the business and engineering teams grow more familiar with NoSQL databases and key principles, leaders can make more informed decisions about how to design the business' overall data architecture.

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}