Reactive Event Streaming Architecture With Kafka, Redis Streams, Spring Boot, and HTTP Server-Sent Events (SSE)
A guide to streaming events from Kafka to Redis, using SSE to ensure only relevant events are processed and sent to individual client IDs.
Join the DZone community and get the full member experience.
Join For FreeThis article outlines a solution for streaming events from Kafka, forwarding them to Redis using its Stream API, and reading individual streams from Redis via its streaming API. The added complexity in this scenario is the need to stream events from an HTTP endpoint using Server-Sent Events (SSE) while ensuring that only events relevant to a specific client ID are processed and sent.
Problem Statement
Many companies have an existing Kafka infrastructure where events are being produced. Our goal is to set up a system that subscribes to Kafka messages but only processes events relevant to a specific client ID. These filtered events should be forwarded to Redis using its Stream API. Additionally, we need to establish an HTTP endpoint for Server-Sent Events (SSE) that allows the specified client to receive real-time event updates.
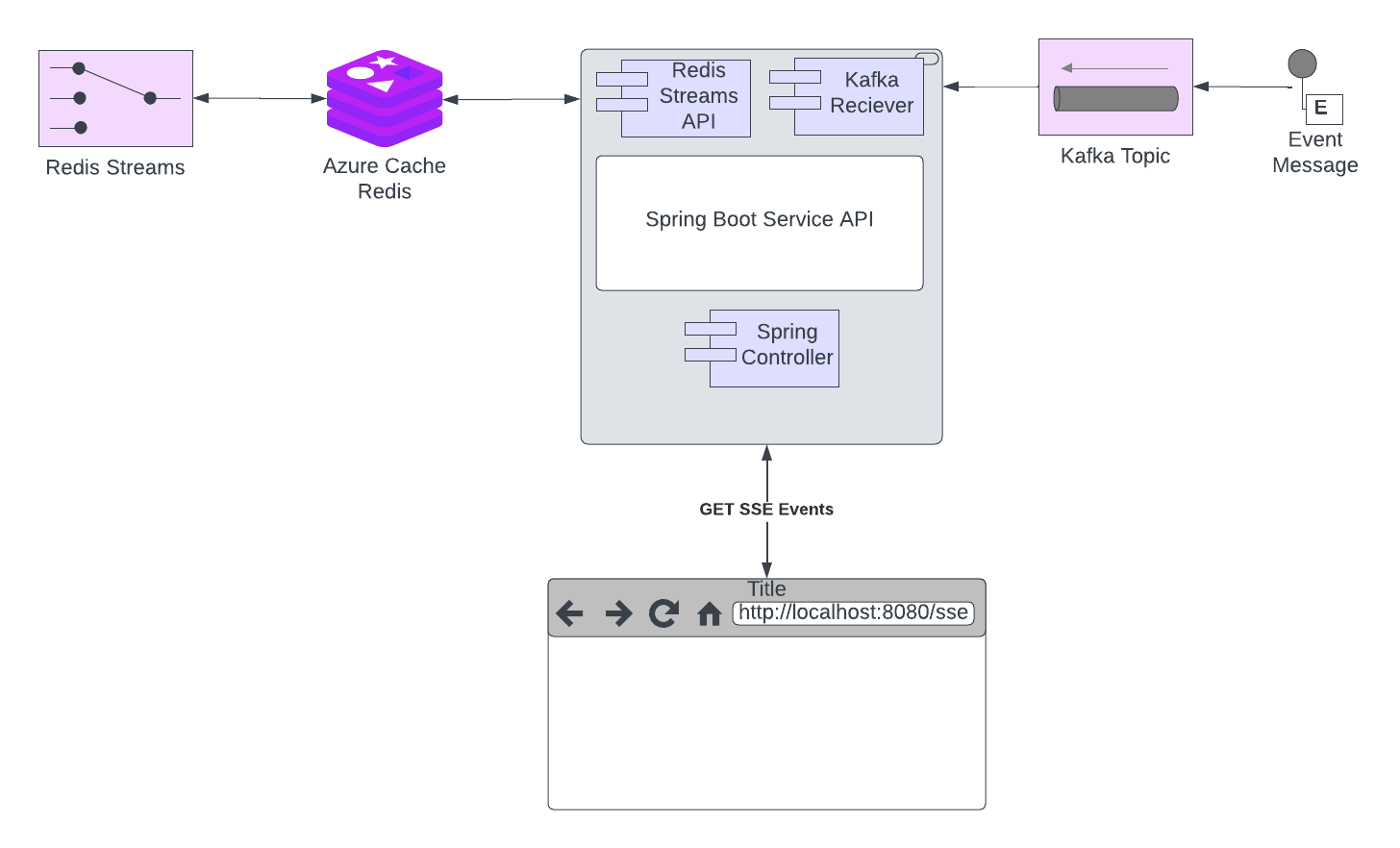
Solution Architecture Overview
The architecture consists of the following components:
- Kafka: A distributed event streaming platform that allows you to publish and subscribe to streams of records (events).
- Spring Boot: A framework for building Java applications. We'll use it to create Kafka consumers and Redis Stream producers. Subscribes to Kafka messages, filters events based on the client ID, and forwards relevant events to Redis Streams.
- Redis: A high-performance, in-memory data store. We'll use its Streams feature to handle event streams. Stores the streamed events using its Streams API.
- Docker: A containerization platform. We'll use Docker and Docker-Compose to create containers for Kafka, Redis, and our Spring Boot application. We will utilize this for a local POT, POC.
- HTTP Server-Sent Events (SSE) Endpoint: Provides real-time event updates to the client, filtering events based on the client ID.
Redis Streams
Redis Streams is a feature in Redis that provides a way to handle real-time data streams with various use cases. Here are some scenarios where you might want to use Redis Streams:
- Real-Time Event Processing: Redis Streams are excellent for processing and storing real-time events. You can use it for things like logging, monitoring, tracking user activities, or any use case that involves handling a continuous stream of events.
- Task Queues: If you need a reliable and distributed task queue, Redis Streams can be a great choice. It allows you to push tasks into a stream and have multiple consumers process those tasks concurrently.
- Activity Feeds: If you're building a social network or any application that requires activity feeds, Redis Streams can efficiently handle the feed data, ensuring fast access and scalability.
- Message Brokering: Redis Streams can serve as a lightweight message broker for microservices or other distributed systems. It can handle message routing and ensure that messages are delivered to interested consumers.
- Real-Time Analytics: When you need to analyze data in real-time, Redis Streams can be useful for storing the incoming data and then processing and aggregating it using Redis capabilities.
- IoT Data Ingestion: If you're dealing with data from Internet of Things (IoT) devices, Redis Streams can handle the high-throughput and real-time nature of the data generated by these devices.
- Logging and Audit Trails: Redis Streams can be used to store logs or audit trails in real-time, making it easy to analyze and troubleshoot issues.
- Stream Processing: If you need to process a continuous stream of data in a specific order (for example, financial transactions or sensor readings), Redis Streams can help you manage the data in the order it was received.
Prerequisites
- Docker and Docker Compose are installed.
- Basic understanding of Spring Boot, Redis Streams, and Kafka.
- Java 17 or higher
- An HTTP client of your choice. I used [httpie]
Of course, you can get the code here.
Steps
1. Set Up Docker Compose for the Backend Infrastructure and the Spring Boot App
Create a `docker-compose.yml` file to define the services:
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181
networks:
node_net:
ipv4_address: 172.28.1.81
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- 29092:29092
- 9092:9092
- 9093:9093
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092,,EXTERNAL://172.28.1.93:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
networks:
node_net:
ipv4_address: 172.28.1.93
cache:
image: redis:6.2-alpine
#image: redis:5.0.3-alpine
restart: always
ports:
- '6379:6379'
#command: redis-server --save 20 1 --loglevel warning --requirepass eYVX7EwVmmxKPCDmwMtyKVge8oLd2t81
command: redis-server /usr/local/etc/redis/redis.conf --loglevel verbose --save 20 1
volumes:
- cache:/data
- ./redis.conf:/usr/local/etc/redis/redis.conf
- $PWD/redis-data:/var/lib/redis
#environment:
# - REDIS_REPLICATION_MODE=master
networks:
node_net:
ipv4_address: 172.28.1.79
volumes:
cache:
driver: local
networks:
node_net:
ipam:
driver: default
config:
- subnet: 172.28.0.0/16Create the yaml for the application 'sse-demo.yml'.
version: "3.8"
services:
sse-demo:
image: "sse/spring-sse-demo:latest"
ports:
- "8080:8080"
#- "51000-52000:51000-52000"
env_file:
- local.env
environment:
- REDIS_REPLICATION_MODE=master
- SPRING_PROFILES_ACTIVE=default
- REDIS_HOST=172.28.1.79
- REDIS_PORT=6379
- KAFKA_BOOTSTRAP_SERVERS=172.28.1.93:9093
networks:
node_net:
ipv4_address: 172.28.1.12
networks:
node_net:
external:
name: docker_node_net2. Create Spring Boot Application
Create a Spring Boot application with the required dependencies:
git checkout https://github.com/glawson6/spring-sse-demo.gitIn `pom.xml,` add the necessary dependencies for Kafka and Redis integration.
3. Implement Kafka Consumer and Redis Stream Producer
Create a Kafka consumer that listens to Kafka events and sends them to Redis Streams. This component also consumes the Redis streams for the HTTP clients:
package com.taptech.sse.event;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.taptech.sse.utils.DurationSupplier;
import com.taptech.sse.utils.ObjectMapperFactory;
import com.taptech.sse.config.SSEProperties;
import jakarta.annotation.PostConstruct;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.context.event.ApplicationStartedEvent;
import org.springframework.context.event.EventListener;
import org.springframework.data.redis.connection.stream.*;
import org.springframework.data.redis.core.ReactiveStringRedisTemplate;
import reactor.core.Disposable;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.kafka.receiver.KafkaReceiver;
import reactor.kafka.receiver.ReceiverRecord;
import reactor.util.function.Tuple2;
import reactor.util.function.Tuples;
import reactor.util.retry.Retry;
import java.nio.ByteBuffer;
import java.time.Duration;
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import java.util.function.Function;
public class DefaultEventReceiverService implements EventReceiverService {
private static final Logger logger = LoggerFactory.getLogger(DefaultEventReceiverService.class);
public final static String TEST_STREAM = "test.stream";
public final static String TEST_STREAM_KEY = "test.stream.key";
public final static String TEST_STREAM_VALUE = "test.stream.value";
private static final String EMPTY_STR = "";
public static final String CLIENT_STREAM_STARTED = "client.stream.started";
public static final String HASH_PREFIX = "hash.";
private static ObjectMapper objectMapper = ObjectMapperFactory.createObjectMapper(ObjectMapperFactory.Scope.SINGLETON);
ReactiveStringRedisTemplate redisTemplate;
KafkaReceiver<String, String> kafkaReceiver;
SSEProperties sseProperties;
StreamReadOptions streamReadOptions;
public DefaultEventReceiverService(ReactiveStringRedisTemplate redisTemplate, KafkaReceiver<String, String> kafkaReceiver,
SSEProperties sseProperties) {
this.redisTemplate = redisTemplate;
this.kafkaReceiver = kafkaReceiver;
this.sseProperties = sseProperties;
this.streamReadOptions = StreamReadOptions.empty().autoAcknowledge()
.block(Duration.of(sseProperties.getClientHoldSeconds(), ChronoUnit.SECONDS));
}
static final Function<String,String> calculateHashKey = str -> new StringBuilder(HASH_PREFIX).append(str).toString();
@PostConstruct
public void init() {
this.redisTemplate.opsForValue().append(TEST_STREAM_KEY, TEST_STREAM_VALUE).subscribe();
}
@EventListener(ApplicationStartedEvent.class)
public Disposable startKafkaConsumer() {
logger.info("############# Starting Kafka listener.....");
return kafkaReceiver.receive()
.doOnError(error -> logger.error("Error receiving event, will retry", error))
.retryWhen(Retry.fixedDelay(Long.MAX_VALUE, Duration.ofSeconds(sseProperties.getTopicRetryDelaySeconds())))
.doOnNext(record -> logger.info("Received event: key {}", record.key()))
.filterWhen(record -> checkIfStreamBeingAccessed(record))
.concatMap(this::handleEvent)
.subscribe(record -> record.receiverOffset().acknowledge());
}
Mono<Boolean> checkIfStreamBeingAccessed(ReceiverRecord<String,String> record){
return this.redisTemplate.opsForHash().hasKey(calculateHashKey.apply(record.key()), CLIENT_STREAM_STARTED)
.doOnNext(val -> logger.info("key => {}'s stream is being accessed {}",record.key(),val));
}
public Mono<ReceiverRecord<String, String>> handleEvent(ReceiverRecord<String, String> record) {
return Mono.just(record)
.flatMap(this::produce)
.doOnError(ex -> logger.warn("Error processing event: key {}", record.key(), ex))
.onErrorResume(ex -> Mono.empty())
.doOnNext(rec -> logger.debug("Successfully processed event: key {}", record.key()))
.then(Mono.just(record));
}
public Mono<Tuple2<RecordId, ReceiverRecord<String, String>>> produce(ReceiverRecord<String, String> recRecord) {
ObjectRecord<String, String> record = StreamRecords.newRecord()
.ofObject(recRecord.value())
.withStreamKey(recRecord.key());
return this.redisTemplate.opsForStream().add(record)
.map(recId -> Tuples.of(recId, recRecord));
}
Function<ObjectRecord<String, String>, NotificationEvent> convertToNotificationEvent() {
return (record) -> {
NotificationEvent event = null;
try {
event = objectMapper.readValue(record.getValue(), NotificationEvent.class);
} catch (JsonProcessingException e) {
e.printStackTrace();
event = new NotificationEvent();
}
return event;
};
}
private Mono<String> createGroup(String workspaceId){
return redisTemplate.getConnectionFactory().getReactiveConnection().streamCommands()
.xGroupCreate(ByteBuffer.wrap(workspaceId.getBytes()), workspaceId, ReadOffset.from("0-0"), true)
.doOnError((error) -> {
if (logger.isDebugEnabled()){
logger.debug("Could not create group.",error);
}
})
.map(okStr -> workspaceId)
.onErrorResume((error) -> Mono.just(workspaceId));
}
private Flux<NotificationEvent> findClientNotificationEvents(Consumer consumer, StreamOffset<String> streamOffset, DurationSupplier booleanSupplier){
return this.redisTemplate.opsForStream().read(String.class, consumer, streamReadOptions, streamOffset)
.map(convertToNotificationEvent())
.repeat(booleanSupplier);
}
public Flux<NotificationEvent> consume(final String clientId){
return Flux.from(createGroup(clientId))
.flatMap(id -> addIdToStream(clientId))
.map(id -> Tuples.of(StreamOffset.create(clientId, ReadOffset.lastConsumed()),
Consumer.from(clientId, clientId),
new DurationSupplier(Duration.of(sseProperties.getClientHoldSeconds(), ChronoUnit.SECONDS), LocalDateTime.now())))
.flatMap(tuple3 -> findClientNotificationEvents(tuple3.getT2(), tuple3.getT1(), tuple3.getT3()));
}
private Mono<String> addIdToStream(String id) {
return this.redisTemplate.opsForHash().put(calculateHashKey.apply(id), CLIENT_STREAM_STARTED, Boolean.TRUE.toString()).map(val -> id);
}
public Flux<Boolean> deleteWorkspaceStream(String workspaceId){
StreamOffset<String> streamOffset = StreamOffset.create(workspaceId, ReadOffset.lastConsumed());
StreamReadOptions streamReadOptions = StreamReadOptions.empty().noack();
Consumer consumer = Consumer.from(workspaceId, workspaceId);
return this.redisTemplate.opsForStream().read(String.class, consumer, streamReadOptions, streamOffset)
.flatMap(objRecord -> this.redisTemplate.opsForStream().delete(workspaceId,objRecord.getId()).map(val -> objRecord))
.flatMap(objRecord -> this.redisTemplate.opsForHash().delete(workspaceId));
}
@Override
public Flux<String> consumeString(String clientId) {
return this.redisTemplate.opsForStream().read(String.class, StreamOffset.latest(clientId)).map(ObjectRecord::getValue);
}
}
4. Configure Services in Spring Boot
cache.provider.name=redis
cache.host=${REDIS_HOST:localhost}
cache.port=${REDIS_PORT:6379}
cache.password=password
# Producer properties
spring.kafka.producer.bootstrap-servers=127.0.0.1:9092
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.group-id=group_id
spring.kafka.boostrap.servers=${KAFKA_BOOTSTRAP_SERVERS:loclahost:9093}
# Common Kafka Properties
auto.create.topics.enable=true
sse.client-hold-seconds=${SSE_CLIENT_HOLD_SECONDS:120}
logging.level.root=INFO
logging.level.com.taptech.sse=DEBUG5. Build Docker Image for Spring Boot App
Using the `kubernetes-maven-plugin` from jkube, create the image for your Spring Boot application:
./mvnw clean package -Dmaven.test.skip=true k8s:build6. Start the Services and Run the Application
From the src/test/resources/docker directory
Start the services:
./startServices.shStart the app:
./start-sse-demo.sh7. Connect to a Stream Using One of the IDS in the client-ids.json File
http --stream GET http://localhost:8080/sse clientId==dd07bd51-1ab0-4e69-a0ff-f625fa9e7fc08. Generate Some Events
You can do an HTTP POST to http://localhost:8080/sse/generateNE
http POST http://localhost:8080/sse/generateNEAfter this, watch as your HTTP client receives an event for the clientId that it is subscribed to.
Discussion
Why would you use Kafka and Redis? Does not Kafka offer this alone? Many companies have invested in Kafka as a backend message provider between their systems. Kafka in itself does not handle message selection very easily.
Message selection is not a typical feature provided natively by Kafka for a couple of reasons:
- Data Size and Latency: Kafka is designed for high-throughput, low-latency message processing. Its architecture focuses on distributing messages to a large number of consumers quickly. Introducing message selection based on arbitrary conditions can slow down the overall processing and introduce latency, which goes against Kafka's primary design goals.
- Idempotency: Kafka relies on the concept of idempotent producers and consumers. This means that if a consumer or producer retries a message due to a failure, it should not result in duplicate processing. Introducing selective message retrieval would complicate this idempotency guarantee, potentially leading to unintended duplicate processing.
- Consumer Offset Tracking: Kafka maintains consumer offsets, allowing consumers to keep track of the last processed message. If message selection is introduced, offsets become less straightforward, as some messages might be skipped based on selection criteria.
- Decoupled Architecture: Kafka is designed to decouple producers from consumers. Producers are unaware of consumer behavior, and consumers can independently decide what messages they want to consume. Message selection would break this decoupling, as producers would need to know which messages to produce based on specific consumer needs.
- Consumer Flexibility: Kafka consumers can be highly flexible in terms of message processing. They can be designed to filter, transform, and aggregate messages based on their own criteria. Introducing message selection at the Kafka level would limit this flexibility and make the system less adaptable to changing consumer requirements.
- Scaling and Parallelism: Kafka's scalability and parallelism benefits come from the ability to distribute messages across multiple partitions and allow multiple consumers to process messages in parallel. Selective message retrieval would complicate this parallelism, making it harder to distribute work efficiently.
While Kafka itself doesn't provide native message selection features, it's essential to design the consumers to handle message filtering and selection if needed. Consumers can be designed to filter and process messages based on specific criteria, ensuring that only relevant messages are processed within the consumer application. This approach allows Kafka to maintain its core design principles while still providing the flexibility needed for various message-processing scenarios.
Kafka could not essentially solve the problem in an easy way, which lead to pushing the messages to another persistent space that could easily select based on known criteria. This requirement leads to the decision to use Redis and allow pushing messages directly to Redis.
A decision was made to limit the events being pushed into Redis based on whether there was a client actually expecting a message. If there were no clients, then Kafka messages were being filtered out.
.filterWhen(record -> checkIfStreamBeingAccessed(record))The client registers the id so that the Kafka listener will push the to the Redis stream.
.flatMap(id -> addIdToStream(clientId))Conclusion
By following the steps outlined in this document, we have successfully implemented an event streaming architecture that takes events from Kafka, filters them based on a specific client ID, and forwards the relevant events to Redis using its Stream API. The SSE endpoint allows clients to receive real-time event updates tailored to their respective client IDs. This solution provides an efficient and scalable way to handle event streaming for targeted clients.
Opinions expressed by DZone contributors are their own.
Comments