The Evolution of Data Pipelines
Explore the evolution of data pipelines over the last few years in this in-depth look at ETL, ELT, and the rise of reverse ETL.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2023 Data Pipelines Trend Report.
For more:
Read the Report
Originally, the term "data pipeline" was focused primarily on the movement of data from one point to another, like a technical mechanism to ensure data flows from transactional databases to destinations such as data warehouses or to aggregate this data for analysis. Fast forward to the present day, data pipelines are no longer seen as IT operations but as a core component of a business's transformation model.
New cloud-based data orchestrators are an example of evolution that allows integrating data pipelines seamlessly with business processes, and they have made it easier for businesses to set up, monitor, and scale their data operations. At the same time, data repositories are evolving to support both operational and analytical workloads on the same engine.
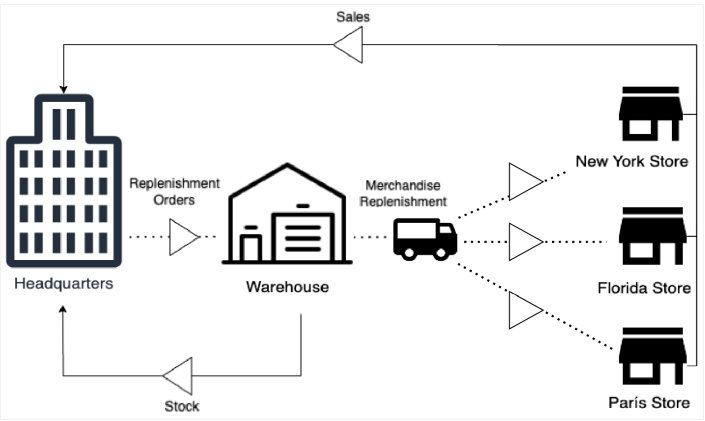
Figure 1: Retail business replenishment process
Consider a replenishment process for a retail company, a mission-critical business process, in Figure 1.
The figure is a clear example of where the new data pipeline approach is having a transformational impact on the business. Companies are evolving from corporate management applications to new data pipelines that include artificial intelligence (AI) capabilities to create greater business impact. Figure 2 demonstrates an example of this.
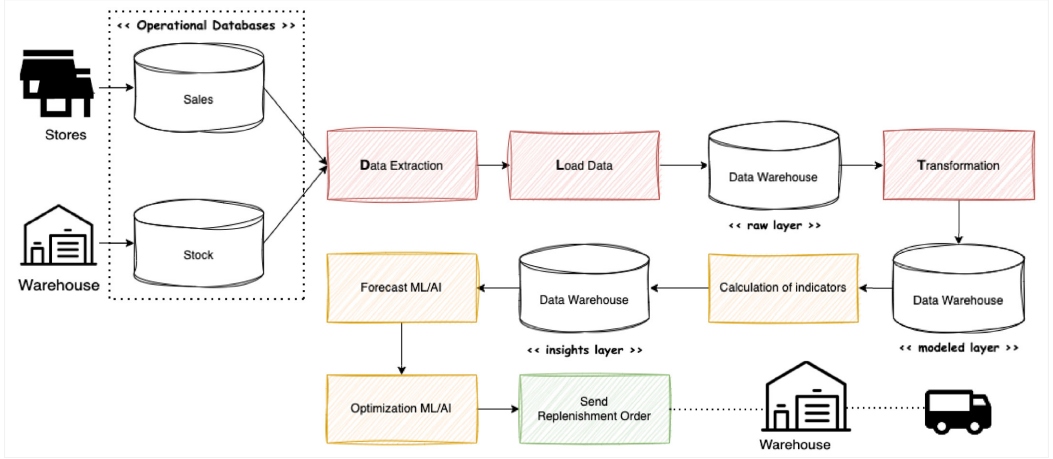
Figure 2: Retail replenishment data pipeline
We no longer see a data process based on data movement, but rather we see a business process that includes machine learning (ML) models or integration with distribution systems. It will be exciting to see how data pipelines will evolve with the emergence of the new generative AI.
Data Pipeline Patterns
All data pipeline patterns are composed of the following stages, although each one of them has a workflow and use cases that make them different:
- Extract – To retrieve data from the source system without modifying it. Data can be extracted from several sources such as databases, files, APIs, streams, or more.
- Transform – To convert the extracted data into final structures that are designed for analysis or reporting. The data transformed is stored in an intermediate staging area.
- Load – To load the transformed data into the final target database.
Currently and after the evolution of data pipelines, these activities are known as data ingestion and determine their pattern as we will see below. Here are some additional activities and components that are now part and parcel of modern data pipelines:
- Data cleaning is a crucial step in the data pipeline process that involves identifying and correcting inconsistencies and inaccuracies in datasets, such as removing duplicate records or handling missing values.
- Data validation ensures the data being collected or processed is accurate, reliable, and meets the specified criteria or business rules. This includes whether the data is of the correct type, falls within a specified range, or that all required data is present and not missing
- Data enrichment improves the quality, depth, and value of the dataset by adding relevant supplementary information that was not originally present with additional information from external sources.
- Machine learning can help enhance various stages of the pipeline from data collection to data cleaning, transformation, and analysis, thus making it more efficient and effective.
Extract, Transform, Load
Extract, transform, load (ETL) is a fundamental process pattern in data warehousing that involves moving data from the source systems to a centralized repository, usually a data warehouse. In ETL, all the load related to the transformation and storage of the raw data is executed in a layer previous to the target system.

Figure 3: ETL data pipeline
The workflow is as follows:
- Data is extracted from the source system.
- Data is transformed into the desired format in an intermediate staging area.
- Transformed data is loaded into the data warehouse.
When to use this pattern:
- Target system performance – If the target database, usually a data warehouse, has limited resources and poor scalability, we want to minimize the impact on performance.
- Target system capacity – When the target systems have limited storage capacity or the GB price is very high, we are interested in transforming and storing the raw data in a cheaper layer.
- Pre-defined structure – When the structure of the target system is already defined.
ETL Use Case
This example is the classic ETL for an on-premise system where, because of the data warehouse computational and storage capacity, we are neither interested in storing the raw data nor in executing the transformation in the data warehouse itself. It is more economical and efficient when it involves an on-premises solution that is not highly scalable or at a very high cost.
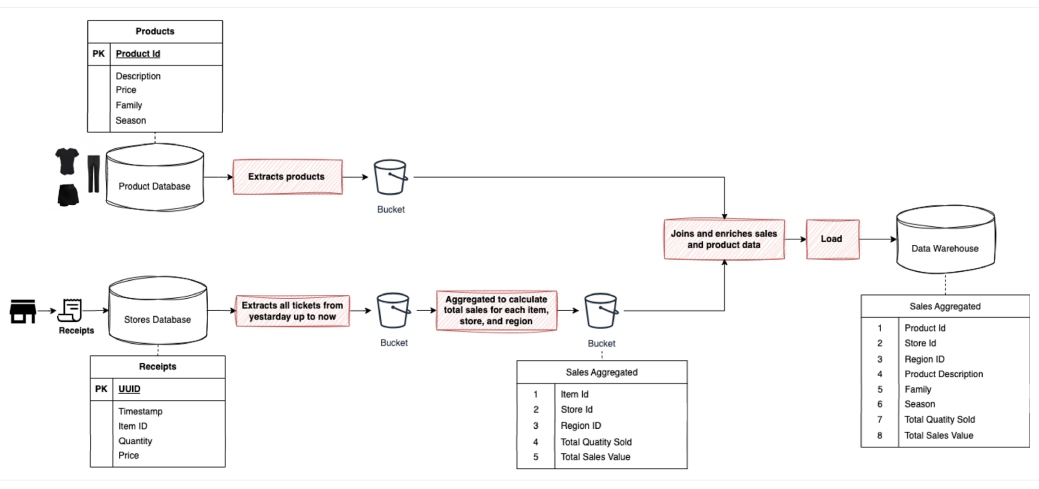
Figure 4: ETL sales insights data pipeline
Extract, Load, Transform
Modern cloud-based data warehouses and data lakes, such as Snowflake or BigQuery, are highly scalable and are optimized for in-house processing that allows for handling large-scale transformations more efficiently in terms of performance and cheaper in terms of cost.
In extract, load, transform (ELT), the data retrieved in the source systems is loaded directly without transformation into a raw layer of the target system. Finally, the following transformations are performed. This pattern is probably the most widely used in modern data stack architectures.

Figure 5: ELT data pipeline
The workflow is as follows:
- Data is extracted from the source system.
- Data is loaded directly into the data warehouse.
- Transformation occurs within the data warehouse itself.
When to use this pattern:
- Cloud-based modern warehouse – Modern data warehouses are optimized for in-house processing and can handle large-scale transformations efficiently.
- Data volume and velocity – When handling large amounts of data or near real-time processing.
ELT Use Case
New cloud-based data warehouse and data lake solutions are high-performant and highly scalable. In these cases, data repositories are better suited for work than external processes. The transformation process can take advantage of new features and run data transformation queries inside the data warehouse faster and at a lower cost.
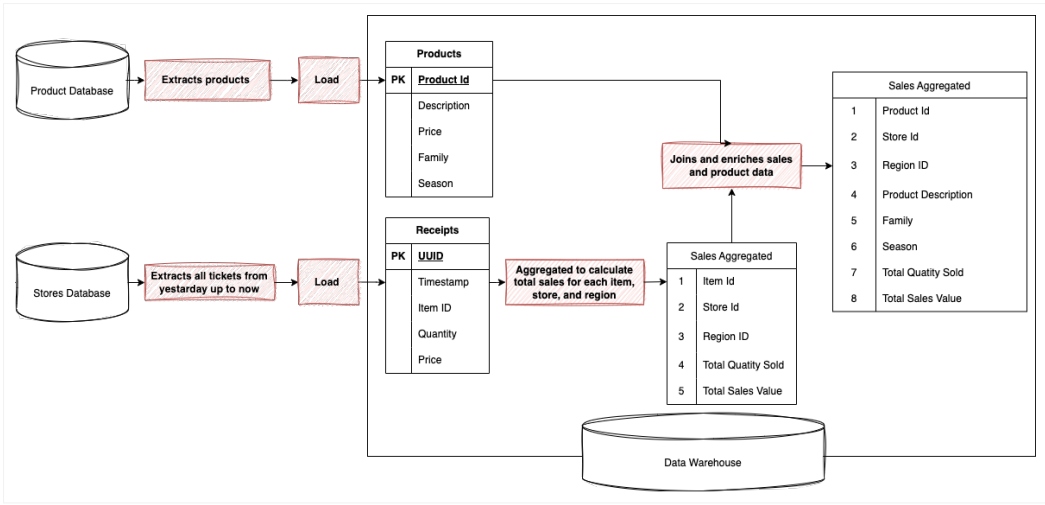
Figure 6: ELT sales insights data pipeline
Reverse ETL
Reverse ETL is a new data pattern that has grown significantly in recent years and has become fundamental for businesses. It is composed of the same stages as a traditional ETL, but functionally, it does just the opposite. It takes data from the data warehouse or data lake and loads it into the operational system.
Nowadays, analytical solutions are generating information with a differential value for businesses and also in a very agile manner. Bringing this information back into operational systems allows it to be actionable across other parts of the business in a more efficient and probably higher impact way.

Figure 7: Reverse ETL data pipeline
The workflow is as follows:
- Data is extracted from the data warehouse.
- Data is transformed into the desired format in an intermediate staging area.
- Data is loaded directly into the operational system.
When to use this pattern:
- Operational use of analytical data – to send back insights to operational systems to drive business processes
- Near real-time business decisions – to send back insights to systems that can trigger near real-time decisions
Reverse ETL Use Case
One of the most important things in e-commerce is to be able to predict what items your customers are interested in; this type of analysis requires different sources of information, both historical and real-time. The data warehouse contains historical and real-time data on customer behavior, transactions, website interactions, marketing campaigns, and customer support interactions. The reverse ETL process enables e-commerce to operationalize the insights gained from its data analysis and take targeted actions to enhance the shopping experience and increase sales.

Figure 8: Reverse ETL customer insights data pipeline
The Rise of Real-Time Data Processing
As businesses become more data-driven, there's an increasing need to have actionable information as quickly as possible. This evolution has driven the transition from batch processing to real-time processing that allows processing the data immediately as it arrives. The advent of new technological tools and platforms that are capable of handling real-time data processing such as Apache Kafka, Apache Pulsar, or Apache Flink have made it possible to build real-time data pipelines.
Real-time analytics became crucial for scenarios like fraud detection, IoT, edge computing, recommendation engines, and monitoring systems. Combined with AI, it allows businesses to make automatic, on-the-fly decisions.
The Integration of AI and Advanced Analytics
Advancements in AI, particularly in areas like generative AI and large language models (LLMs), will transform data pipeline landscape capabilities such as enrichment, data quality, data cleansing, anomaly detection, and transformation automation. Data pipelines will evolve exponentially in the coming years, becoming a fundamental part of the digital transformation, and companies that know how to take advantage of these capabilities will undoubtedly be in a much better position. Some of the activities where generative AI will be fundamental and will change the value and way of working with data pipelines include:
- Data cleaning and transformation
- Anomaly detection
- Enhanced data privacy
- Real-time processing
AI and Advanced Analytics Use Case
E-commerce platforms receive many support requests from customers every day, including a wide variety of questions and responses written in different conversational styles. Increasing the efficiency of the chatbot is so important to improve the customer experience, and many companies decide to implement a chatbot using a GPT model. In this case, we need to provide all information from questions, answers, and technical product documentation that is available in different formats.
The new generative AI and LLM models not only allow us to provide innovative solutions for interacting with humans, but also to increase the capabilities of our data pipelines, such as data cleaning or transcriptions. Training the GPT model requires clean and preprocessed text data. This involves removing any personally identifiable information, correcting spelling, correcting grammar mistakes, or removing any irrelevant information. A GPT model can be trained to perform these tasks automatically.
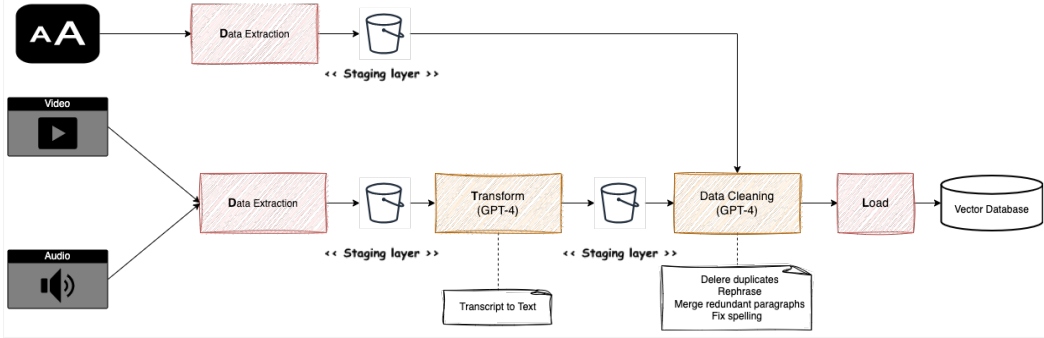
Figure 9: ETL data pipeline with AI for chatbot content ingestion
Conclusion
Data pipelines have evolved a lot in the last few years, initially with the advent of streaming platforms and later with the explosion of the cloud and new data solutions. This evolution means that every day they have a greater impact on business value, moving from a data movement solution to a key element in the business transformation. The explosive growth of generative AI solutions in the last year has opened up an exciting path, as they have a significant impact on all stages of the data pipelines; therefore, the near future is undoubtedly linked to AI.
Such a disruptive evolution requires the adaptation of organizations, teams, and engineers to enable them to use the full potential of technology. The data engineer role must evolve to acquire more business and machine learning skills. This is a new digital transformation, and perhaps the most exciting and complex movement in recent decades.
This is an article from DZone's 2023 Data Pipelines Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments