Kubernetes Today
Delve into the serverless trend advantages and highlight key open-source solutions that bridge the gap between serverless and Kubernetes.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2023 Kubernetes in the Enterprise Trend Report.
For more:
Read the Report
Kubernetes, a true game-changer in the domain of modern application development, has revolutionized the way we manage containerized applications. Some people tend to think that Kubernetes is an opposing approach to serverless. This is probably because of the management bound in deploying applications to Kubernetes — the node management, service configuration, load management, etc. Serverless computing, celebrated for its autoscaling power and cost-efficiency, is known for its easy application development and operation. Yet, the complexities Kubernetes introduces have led to a quest for a more automated approach — this is precisely where serverless computing steps into Kubernetes.
In this exploration, we'll delve into the serverless trend advantages and highlight key open-source solutions that bridge the gap between serverless and Kubernetes, examining their place in the tech landscape.
Factors Driving Kubernetes' Popularity
Kubernetes has experienced a meteoric rise in popularity among experienced developers, driven by several factors:
- Extensibility – Kubernetes offers custom resource definitions (CRDs) that empower developers to define and manage complex application architectures according to their requirements.
- Ecosystem – Kubernetes fosters a rich ecosystem of tools and services, enhancing its adaptability to various cloud environments.
- Declarative configuration – Kubernetes empowers developers through declarative configuration, which allows developers to define desired states and lets the system handle the rest.
Kubernetes Challenges: Understanding the Practical Complexities
That being said, experienced developers navigating the intricate landscape of Kubernetes are familiar with the complexities of setting up, configuring, and maintaining Kubernetes clusters. One of the common challenges is scaling. While manual scaling is becoming a thing of the past, autoscaling has become the de facto standard, with organizations who deploy in Kubernetes benefiting from native autoscaling capabilities such as horizontal pod autoscaling (HPA) and vertical pod autoscaling (VPA).
Figure 1: HorizontalPodAutoscaler
Nonetheless, these solutions are not without their constraints. HPA primarily relies on resource utilization metrics (e.g., CPU and memory) for scaling decisions. For applications with unique scaling requirements tied to specific business logic or external events, HPA may not provide the flexibility needed.
Furthermore, consider the challenge HPA faces in scaling down to zero Pods. Scaling down to zero Pods can introduce complexity and safety concerns. It requires careful handling of Pod termination to ensure that in-flight requests or processes are not disrupted, which can be challenging to implement safely in all scenarios.
Understanding Serverless Computing
Taking a step back in time to 2014, AWS introduced serverless architectures, which fully exemplified the concept of billing accordingly and using resources only when, how much, and for as long as they're needed. This approach offers two significant benefits: Firstly, it frees up teams from worrying about how applications run, enabling them to concentrate solely on business matters; secondly, it minimizes the hardware, environmental impact, and thus has a positive financial impact on running applications to the absolute minimum.
It's essential to understand that "serverless" doesn't imply that there is no server. Instead, it means you don't have to concern yourself with the server responsible for executing tasks; your focus remains solely on the tasks themselves.
Serverless Principles in Kubernetes
Serverless computing is on the rise, and in some ways, it's getting along with the growing popularity of event-driven architecture, which makes this pairing quite potent.

Figure 2: Serverless advantages
Event-driven designs are becoming the favored method for creating robust apps that can respond to real-world events in real time. In an event-driven pattern, the crucial requirement is the capability to respond to varying volumes of events at different rates and to dynamically scale your application accordingly. This is where serverless technology perfectly aligns and dynamically scales the application infrastructure accordingly.
When you combine the event-driven approach with serverless platforms, the benefits are twofold: You not only save on costs by paying only for what you need, but you also enhance your app's user experience and gain a competitive edge as it syncs with real-world happenings.
Who Needs Serverless in Kubernetes?
In practical terms, serverless integration in Kubernetes is beneficial for software development teams aiming to simplify resource management and reduce operational complexity. Additionally, it offers advantages to organizations looking to optimize infrastructure costs while maintaining agility in deploying and scaling applications.
Explore a Real-World Scenario
To illustrate its practicality, imagine a data processing pipeline designed around the producer-consumer pattern. The producer-consumer pattern allows independent operation of producers and consumers, efficient resource utilization, and scalable concurrency. By using a buffer and coordination mechanisms, it optimizes resource usage and ensures orderly data processing. In this architectural context, Kubernetes and KEDA demonstrate significant potential.
Producer-Consumer Serverless Architecture With KEDA
The system works as the following — producers generate data that flows into a message queue, while consumers handle this data asynchronously. KEDA dynamically fine tunes the count of consumer instances in response to changes within the message queue's activity, ensuring optimal resource allocation and performance.
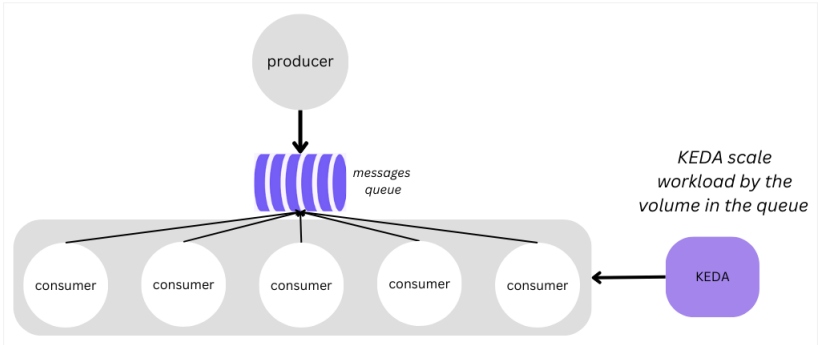
Figure 3: Producer-consumer architecture based on KEDA
This efficient serverless architecture includes:
- Message queue – Selected message queue system that is compatible with Kubernetes. Once chosen, it has to be configured to enable accessibility for both producers and consumers.
- Producer – The producer component is a simple service that is responsible for generating the tasks and pushing data into the message queue.
- Consumer– Consumer applications are capable of pulling data asynchronously from the message queue. These applications are designed for horizontal scalability to handle increased workloads effectively. The consumers are deployed as Pods in Kubernetes and utilized by KEDA for dynamic scaling based on queue activity.
- It's essential to note that while the application operates under KEDA's management, it remains unaware of this fact. Other than that, in this kind of dynamic scale, it is important to highly prioritize robust error handling, retries, and graceful shutdown procedures within the consumer application to ensure reliability and fault tolerance.
- KEDA– The KEDA system contains scalers that are tailored to the message queue and scaling rules that cater to the system's unique requirements. KEDA offers multiple options to configure the events delivery to the consumers on various metrics such as queue length, message age, or other relevant indicators.
- For example, if we choose setting the
queueLengthas target and if one Pod can effectively process 10 messages, you can set thequeueLengthtarget to 10. In practical terms, this means that if the actual number of messages in the queue exceeds this threshold, say it's 50 messages, the scaler will automatically scale up to five Pods to efficiently handle the increased workload. Other than that, an upper limit can be configured by themaxReplicaCountattribute to prevent excessive scaling. - The triggers are configured by the following format:
- For example, if we choose setting the
triggers:
- type: rabbitmq
metadata:
host: amqp://localhost:5672/vhost
protocol: auto
mode: QueueLength
value: "100.50"
activationValue: "10.5"
queueName: testqueue
unsafeSsl: trueLet's go over this configuration: It sets up a trigger for RabbitMQ queue activity. This monitors the testqueue and activates when the queue length exceeds the specified threshold of 100.50. When the queue length drops below 10.5, the trigger deactivates. The configuration includes the RabbitMQ server's connection details, using the auto protocol detection and potentially unsafe SSL settings. This setup enables automated scale in response to queue length changes.
The architecture achieves an effortlessly deployable and intelligent solution, allowing the code to concentrate solely on essential business logic without the distraction of scalability concerns. This was just an example; the producer-consumer serverless architecture can be implemented through a variety of robust tools and platforms other than KEDA. Let's briefly explore another solution using Knative.
Example: Architecture Based on Knative
The implementation of the Knative-based system distinguishes itself by assuming the responsibility for data delivery management, in contrast to KEDA, which does not handle data delivery and requires you to set up data retrieval. Prior to deployment of the Knative-based system, it is imperative to ensure its environment is equipped with Knative Serving and Eventing components.
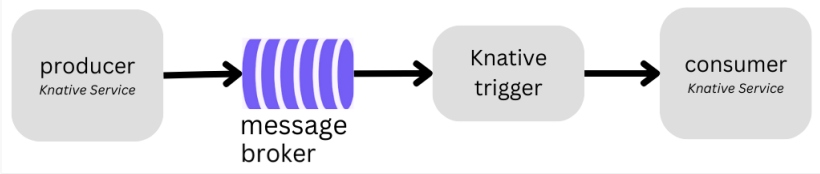
Figure 4: Producer-consumer architecture based on Knative
The architecture can include:
- Message broker – Selected message queue that seamlessly integrates as a Knative Broker like Apache Kafka or RabbitMQ.
- Producer – The producer component is responsible for generating the tasks and dispatching them to a designated message queue within the message broker, implemented as Knative Service.
- Trigger – The Knative trigger establishes the linkage between the message queue and the consumer, ensuring a seamless flow of messages from the broker to the consumer service.
- Consumer – The consumer component is configured to efficiently capture these incoming messages from the queue through the Knative trigger, implemented as Knative Service.
All of this combined results in an event-driven data processing application that leverages Knative's scaling capabilities. The application automatically scales and adapts to the ever-evolving production requirements of the real world.
Indeed, we've explored solutions that empower us to design and construct serverless systems within Kubernetes. However, the question that naturally arises is: What's coming next for serverless within the Kubernetes ecosystem?
The Future of Serverless in Kubernetes
The future of serverless in Kubernetes is undeniably promising, marked by recent milestones such as KEDA's acceptance as a graduated project and Knative's incubating project status. This recognition highlights the widespread adoption of serverless concepts within the Kubernetes community. Furthermore, the robust support and backing from major industry players underscores the significance of serverless in Kubernetes. Large companies have shown their commitment to this technology by providing commercial support and tailored solutions.
It's worth highlighting that the open-source communities behind projects like KEDA and Knative are the driving force behind their success. These communities of contributors, developers, and users actively shape the projects' futures, fostering innovation and continuous improvement. Their collective effort ensures that serverless in Kubernetes remains dynamic, responsive, and aligned with the ever-evolving needs of modern application development.
In short, these open-source communities promise a bright and feature-rich future for serverless within Kubernetes, making it more efficient, cost-effective, and agile.
This is an article from DZone's 2023 Kubernetes in the Enterprise Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments